Netty
Netty is an asynchronous event-driven network application framework
for rapid development of maintainable high performance protocol servers & clients.
Netty 是一款异步事件驱动的网络应用框架,用于快速开发可维护、高性能的协议服务器和客户端。
Netty概述
1.netty 客户端到服务端数据交互
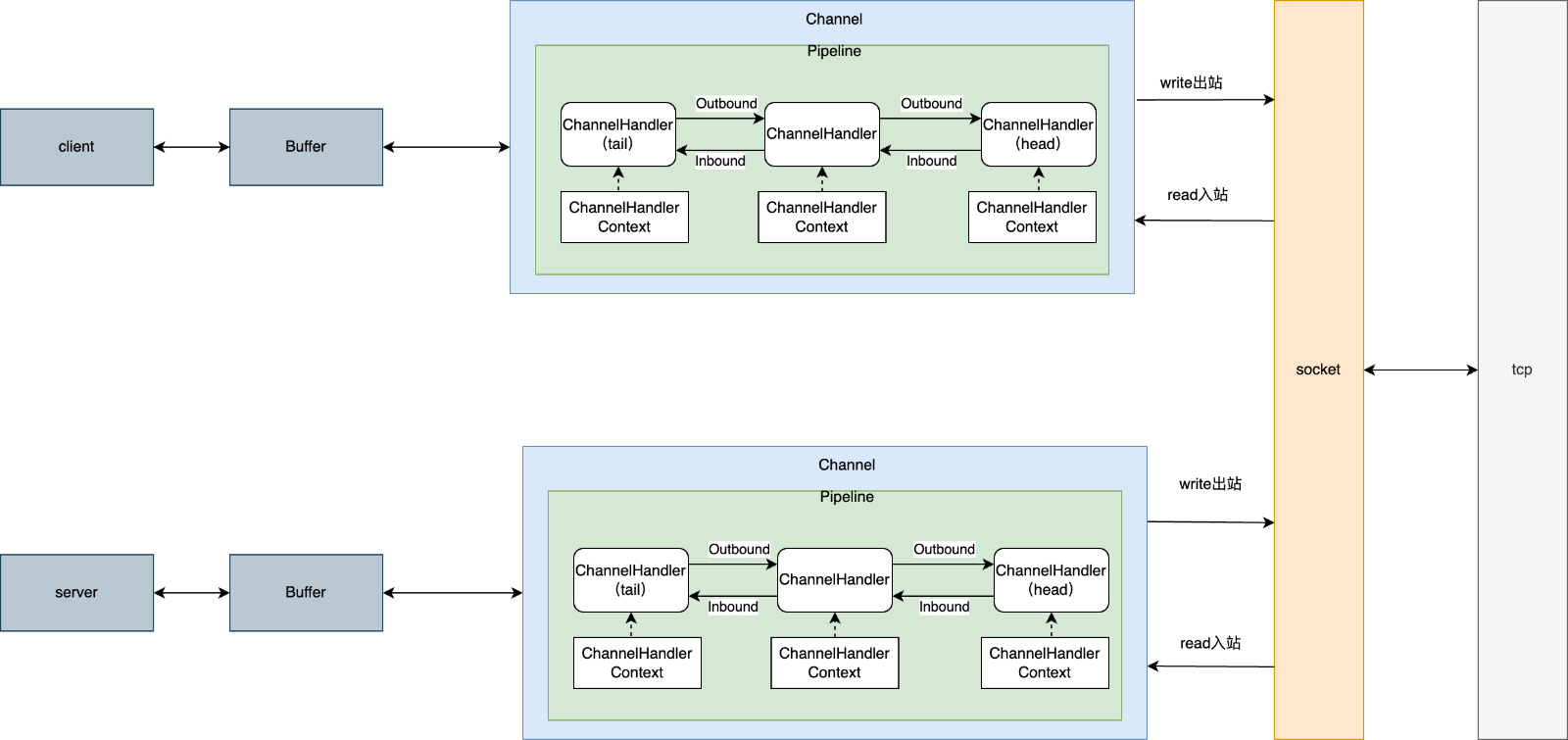
2.源码分析
1.服务端启动
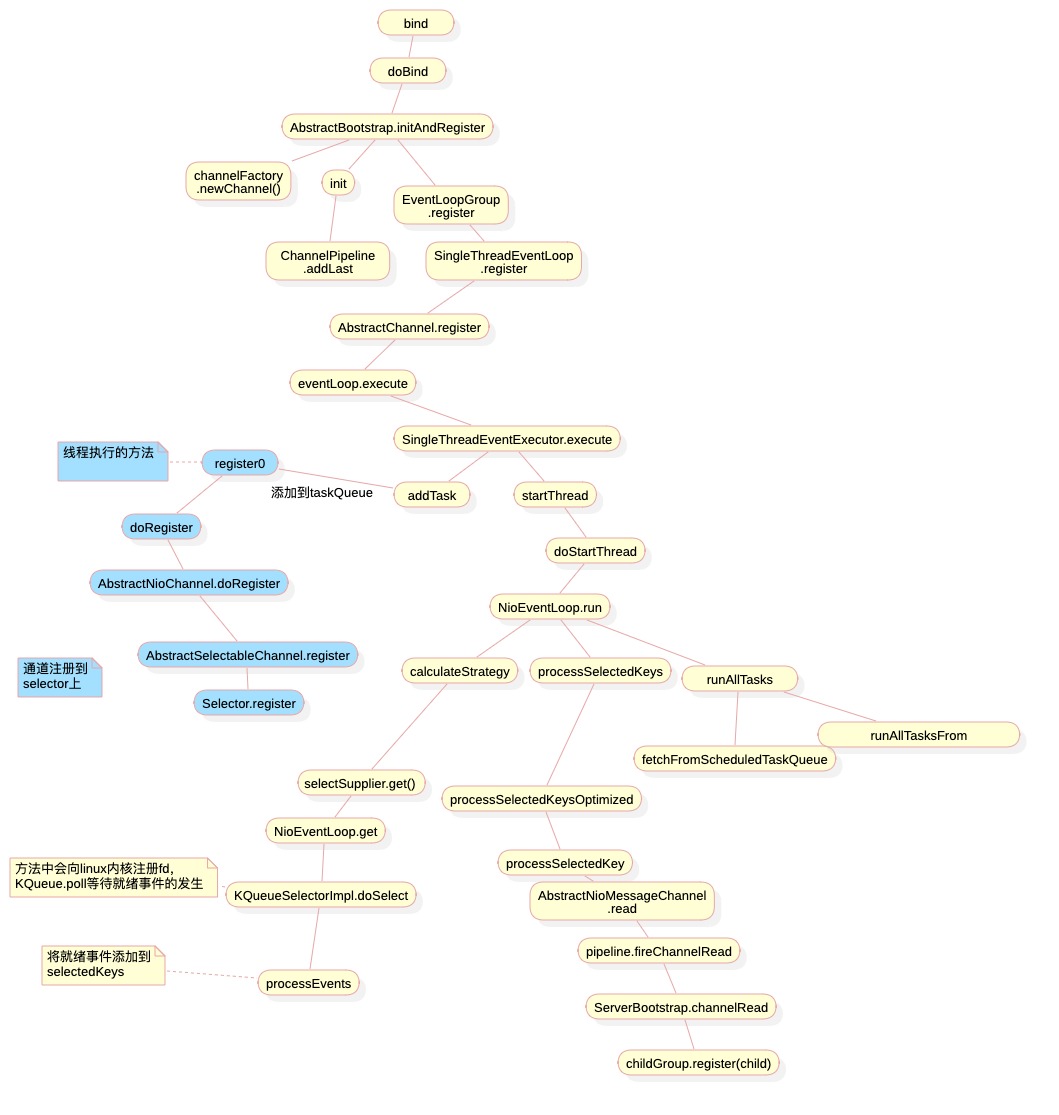
b.bind(8099).sync() 服务启动调用bind方法,然后到register方法,此时EventLoop执行一个任务,任务是调用register0
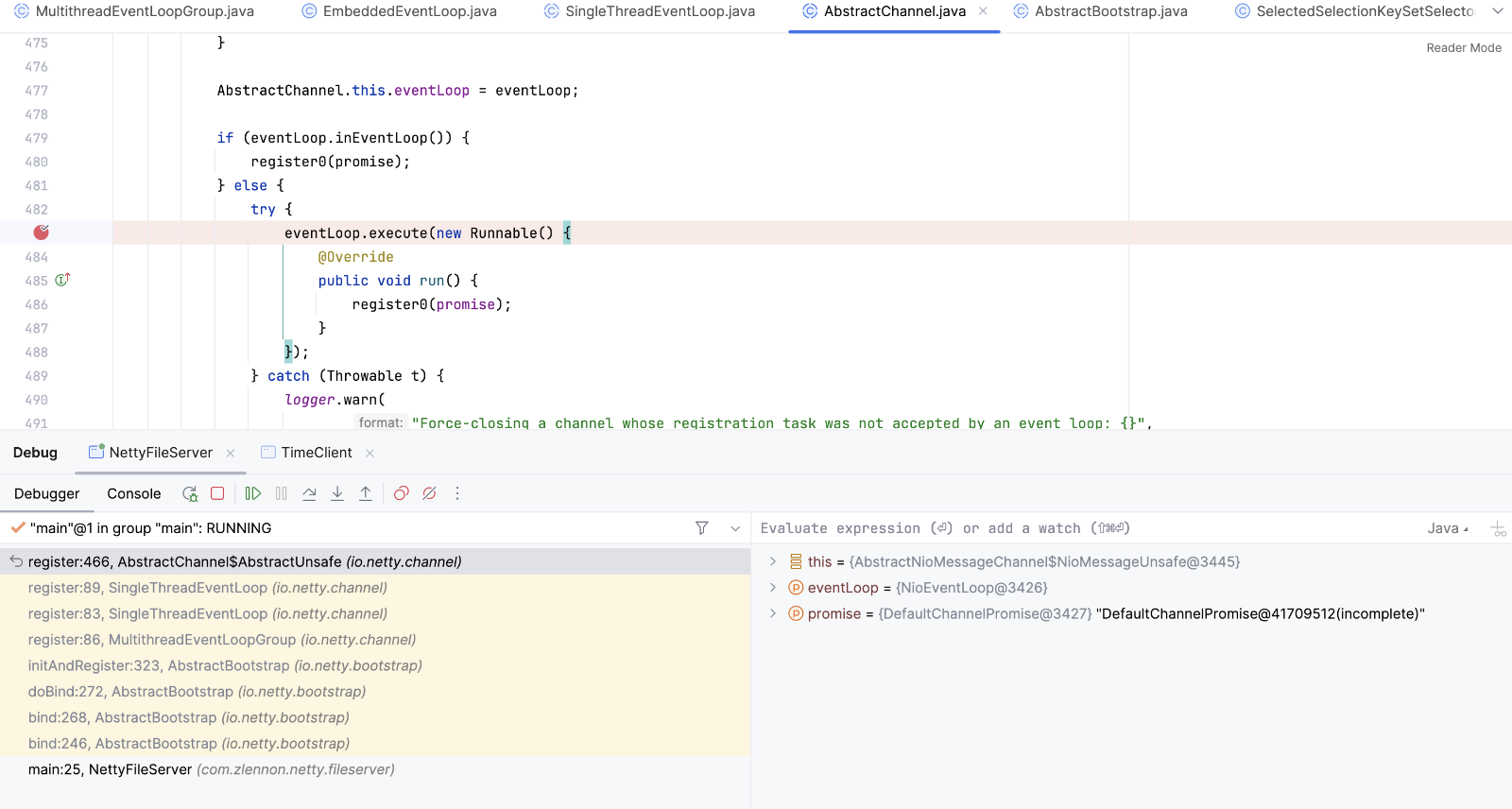
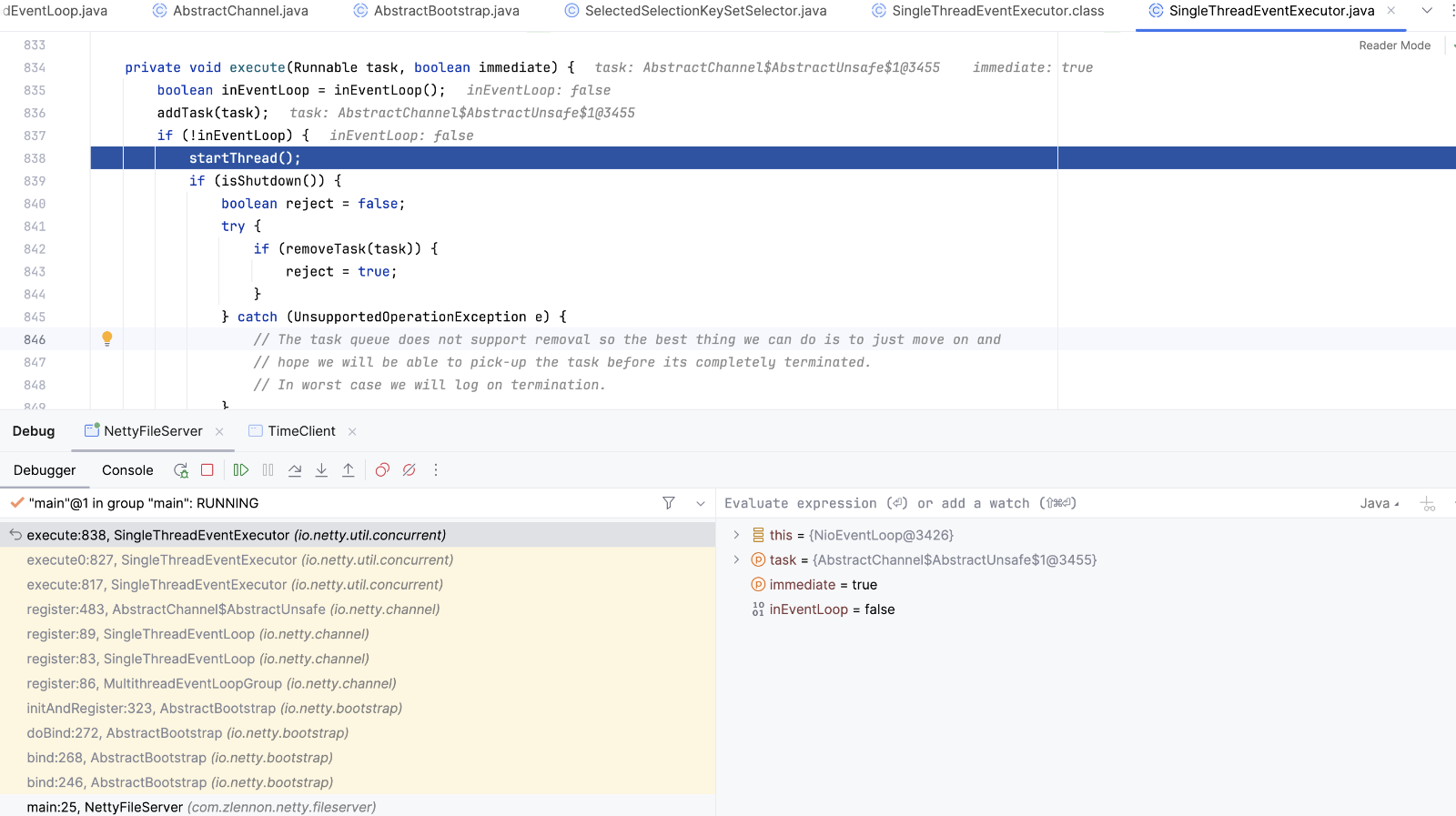
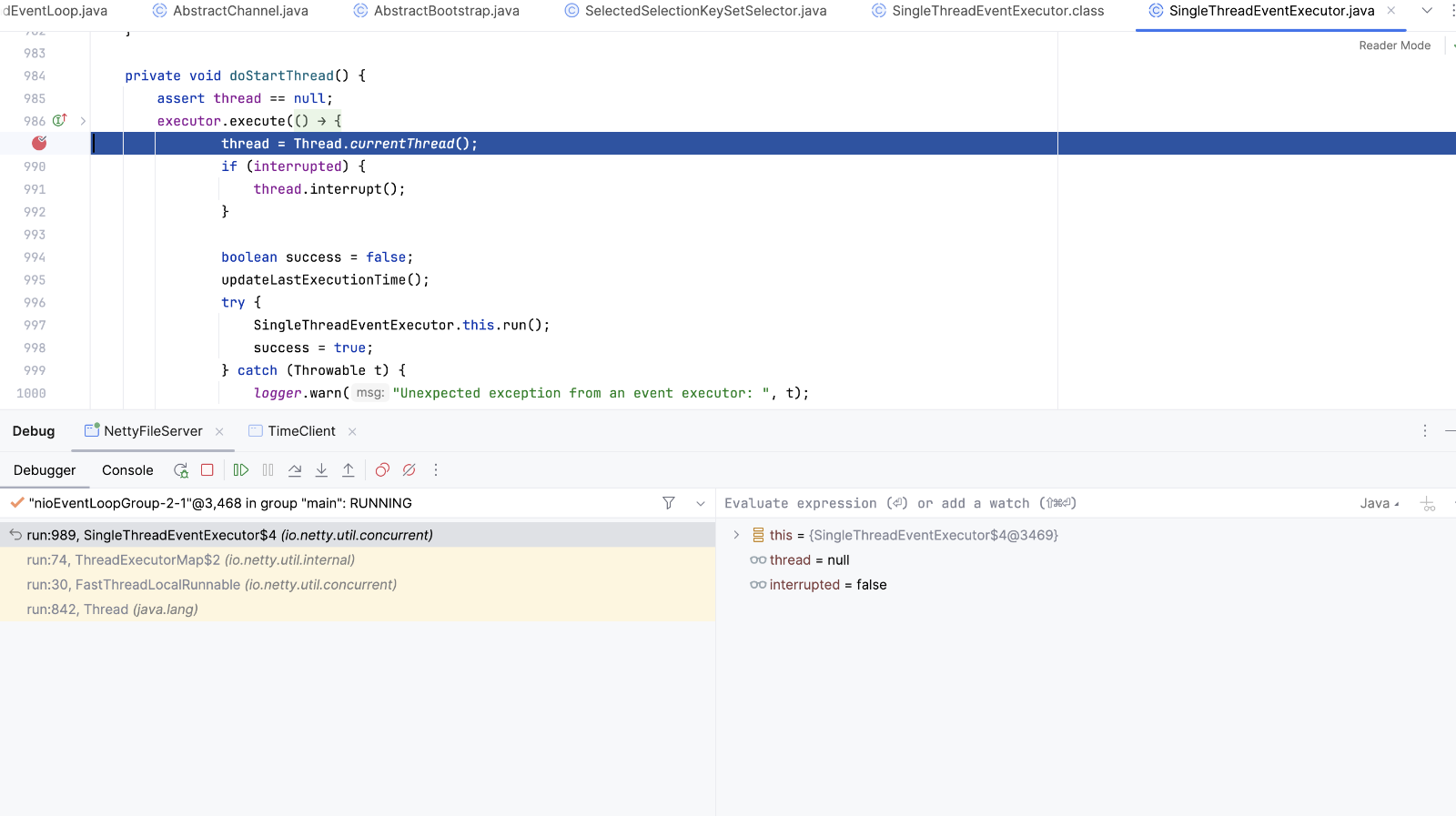
EventLoop.execute方法添加任务到队列中, 并开启Reactor线程
线程开启计算策略
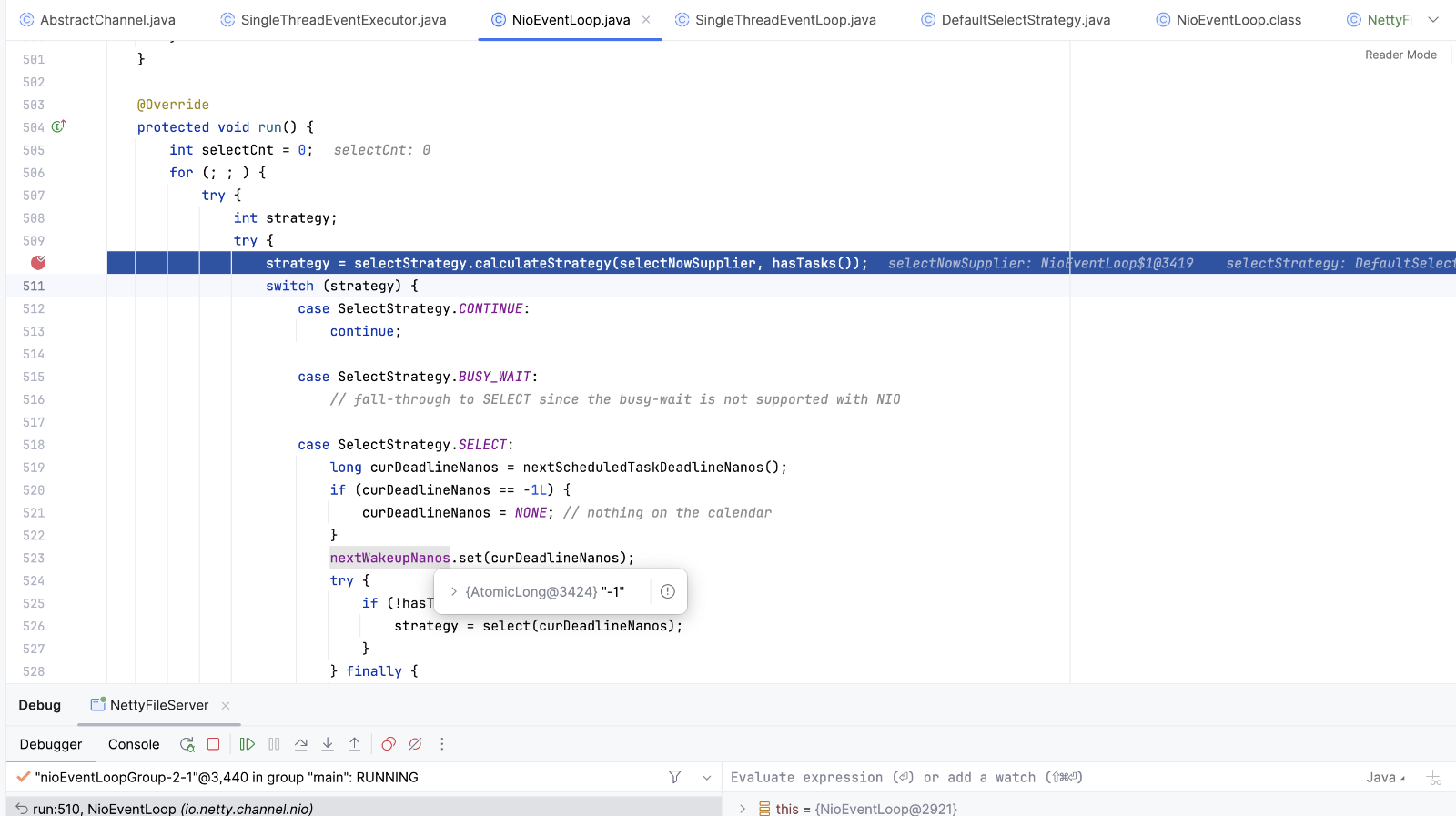
public int calculateStrategy(IntSupplier selectSupplier, boolean hasTasks) throws Exception {
return hasTasks ? selectSupplier.get() : SelectStrategy.SELECT;
}
private final IntSupplier selectNowSupplier = new IntSupplier() {
@Override
public int get() throws Exception {
return selectNow();
}
};
selectSupplier.get selectNow方法 。策略计算完成后 如果不符合判断语句,则执行runalltasks。在前面启动线程的时候 添加了一个runnable,任务是register0方法。执行register方法将通道注册到selector上
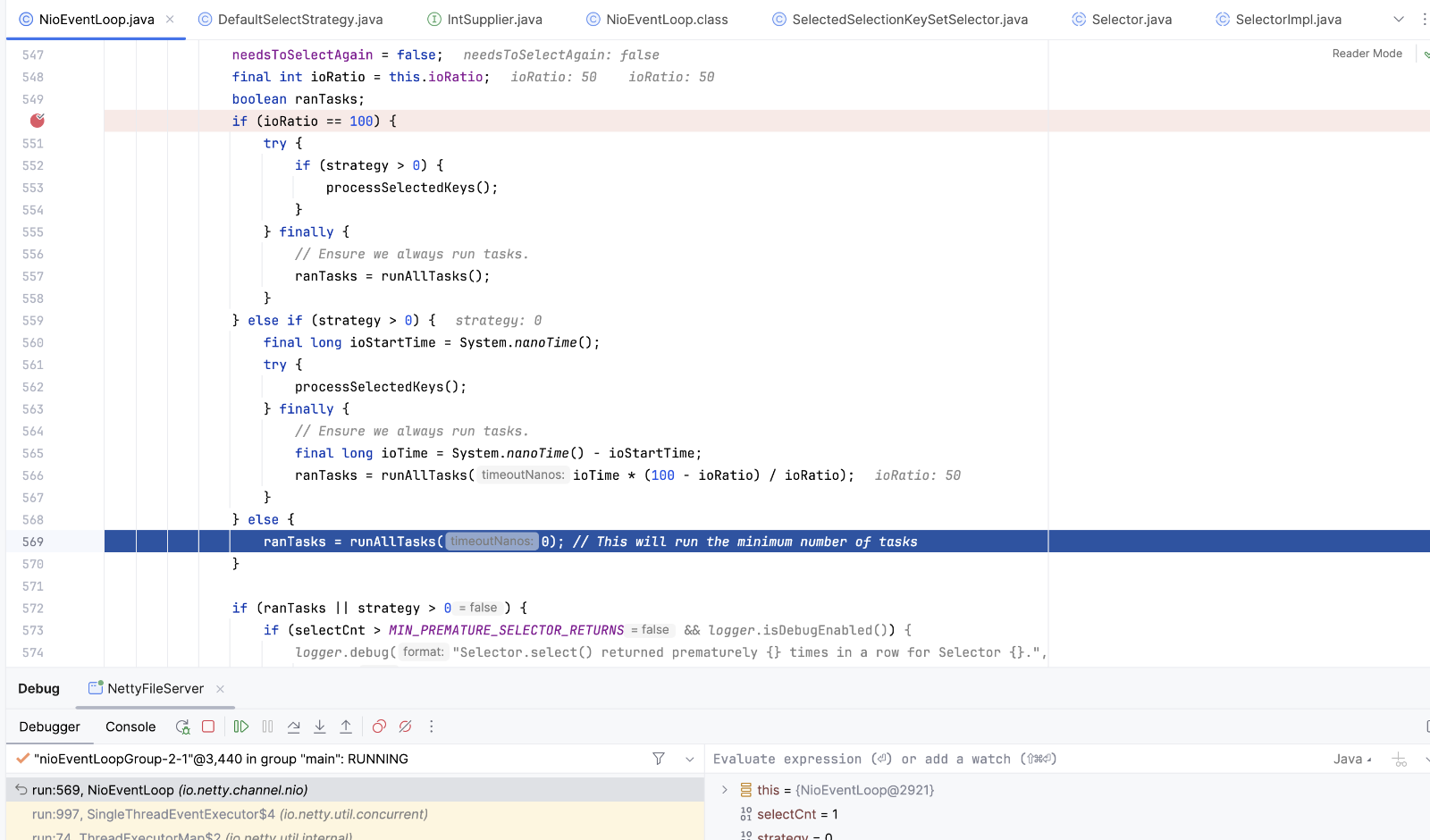
没有任务后线程将阻塞在KQueue.poll(kqfd, pollArrayAddress, MAX_KEVENTS, to);上 等待客户端连接
strategy>0 处理key
else if (strategy > 0) {
final long ioStartTime = System.nanoTime();
try {
processSelectedKeys();
} finally {
// Ensure we always run tasks.
final long ioTime = System.nanoTime() - ioStartTime;
ranTasks = runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
处理读写事件
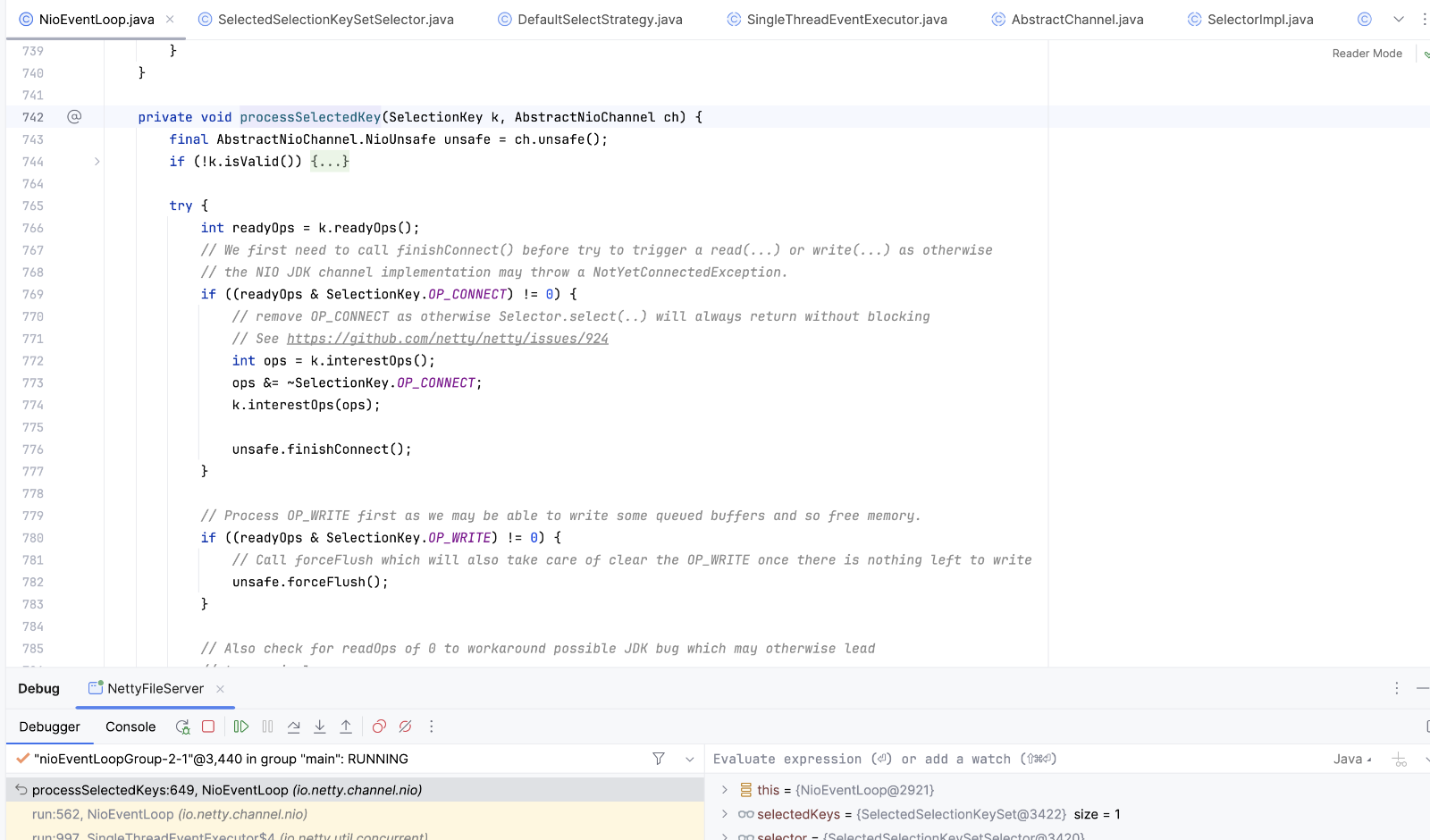
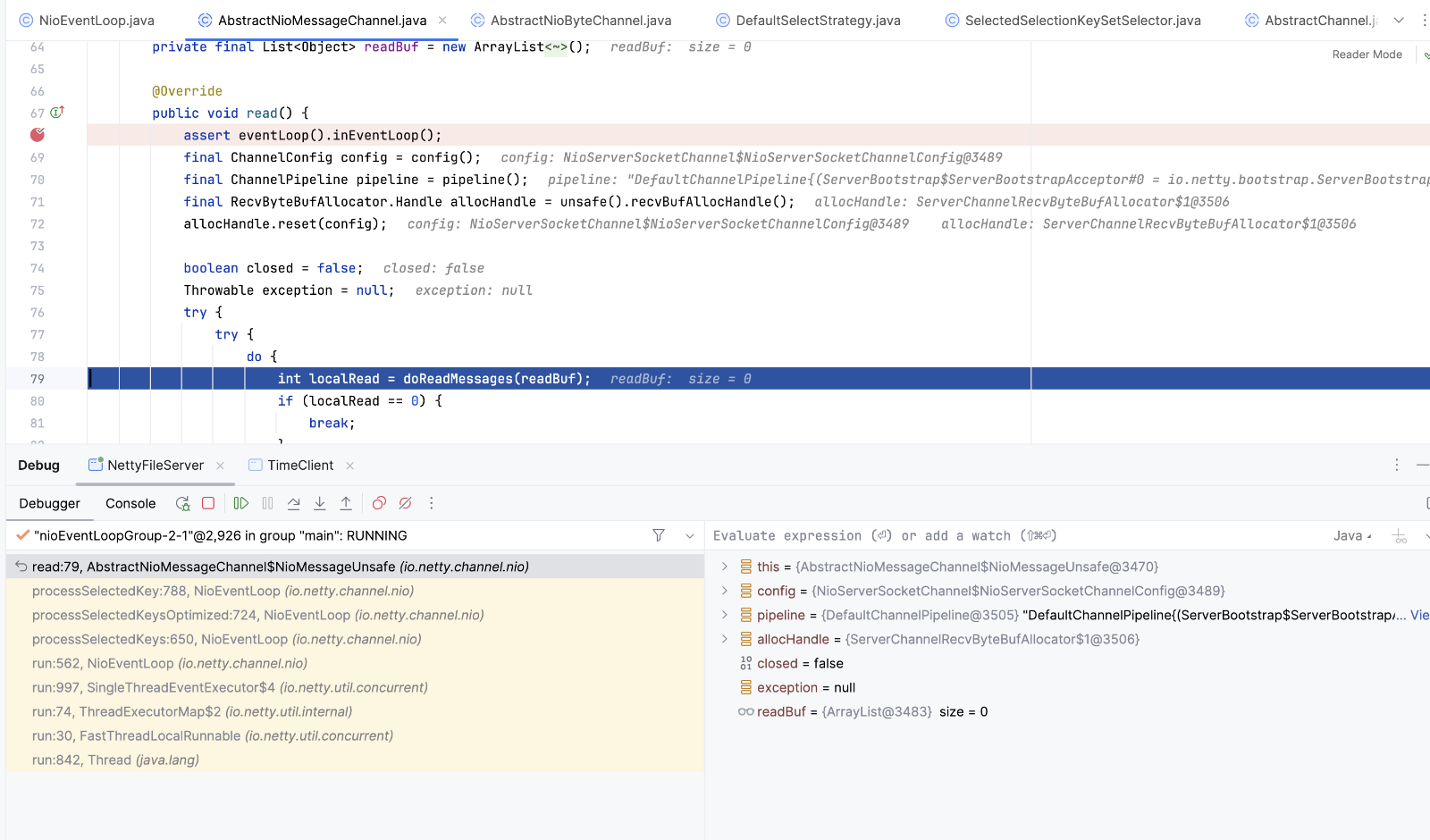
读message ,accept socket 并包装成NioSocketChannel,然后继续调用
pipeline.fireChannelRead(readBuf.get(i)); ->执行AbstractChannelHandlerContext.invokeChannelRead() ,循环执行handler的channelRead方法
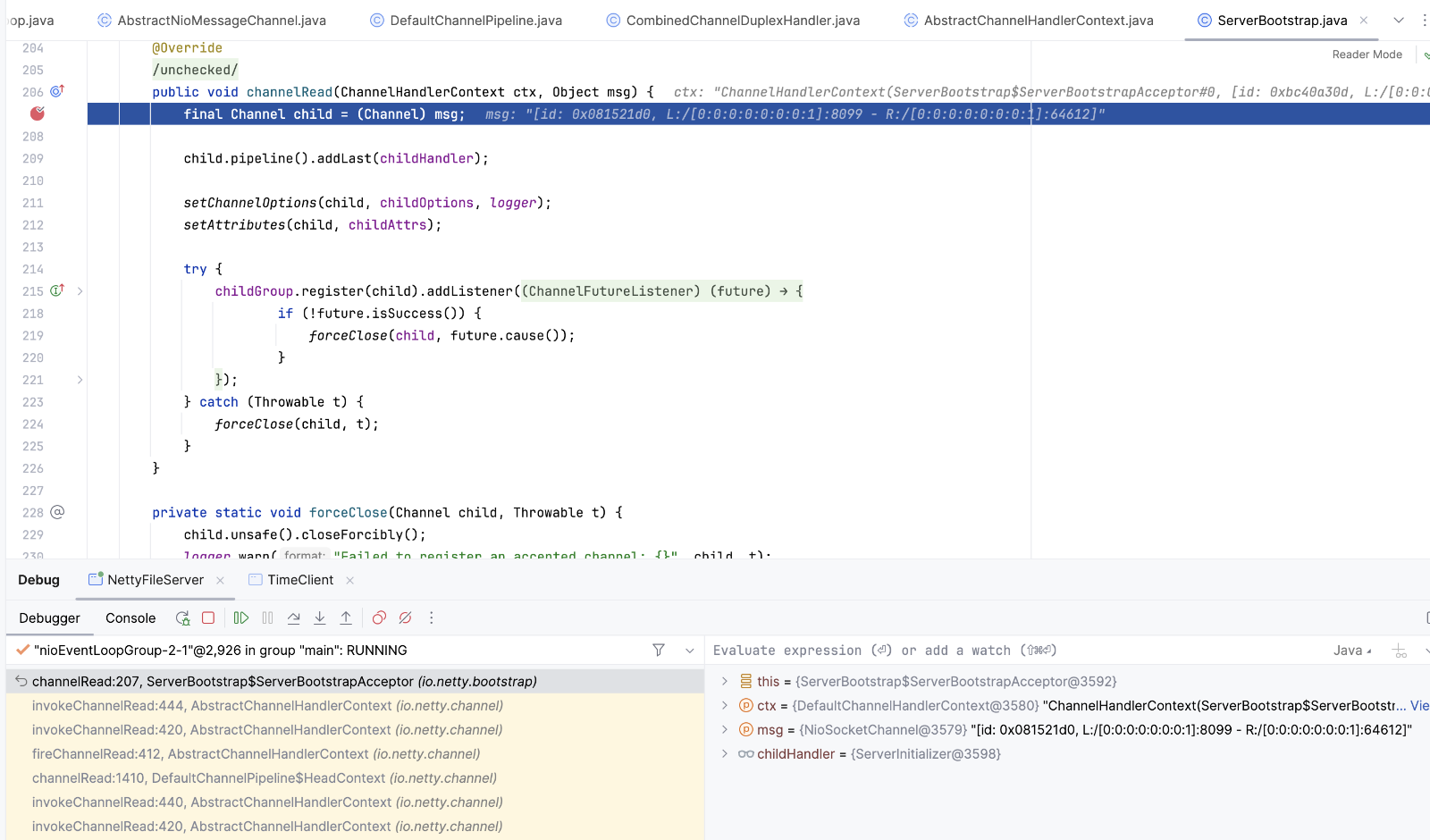
执行到ServerBootstrap$ServerBootstrapAcceptor.channelRead方法时,会将当前通道注册到workGroup上
2.客户端启动
客户端启动和服务端启动基本一致,当处理processSelectedKey时,会进入链接事件
if ((readyOps & SelectionKey.OP_CONNECT) != 0) {
// remove OP_CONNECT as otherwise Selector.select(..) will always return without blocking
// See https://github.com/netty/netty/issues/924
int ops = k.interestOps();
ops &= ~SelectionKey.OP_CONNECT;
k.interestOps(ops);
unsafe.finishConnect();
}
3.类的继承关系
NioEventLoop继承关系
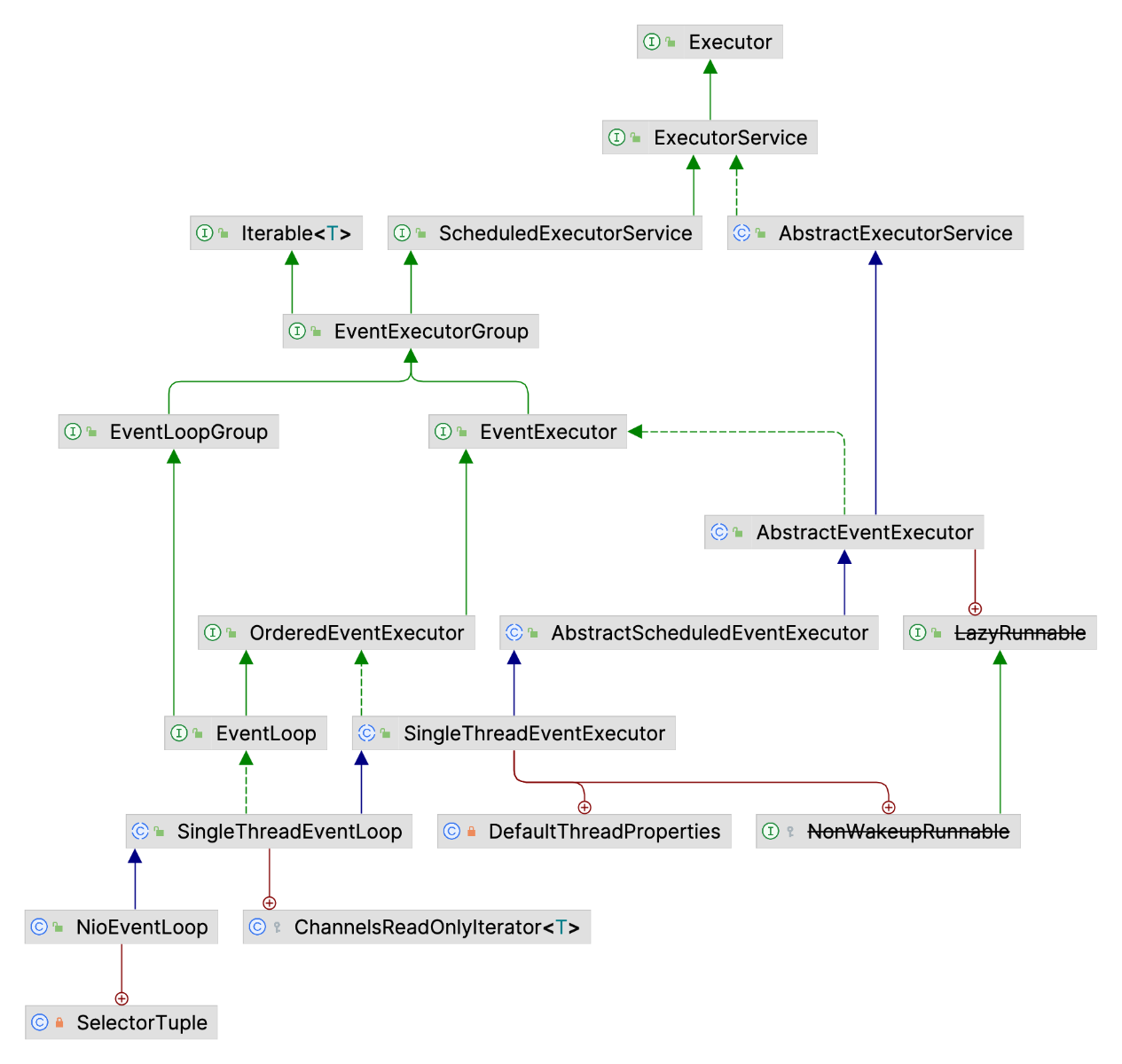
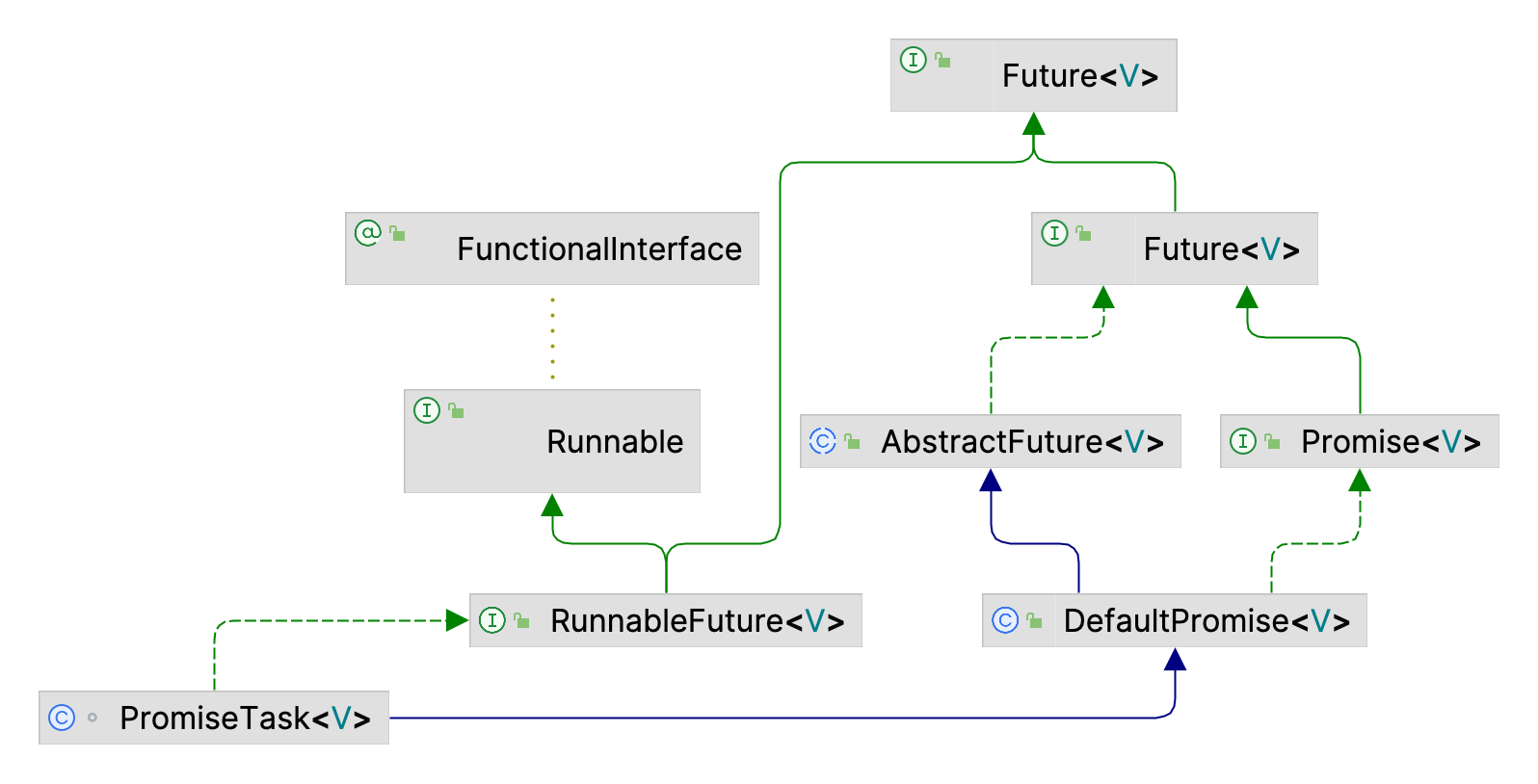
Promise继承关系,Promise扩展了Future,添加了异步通知机制

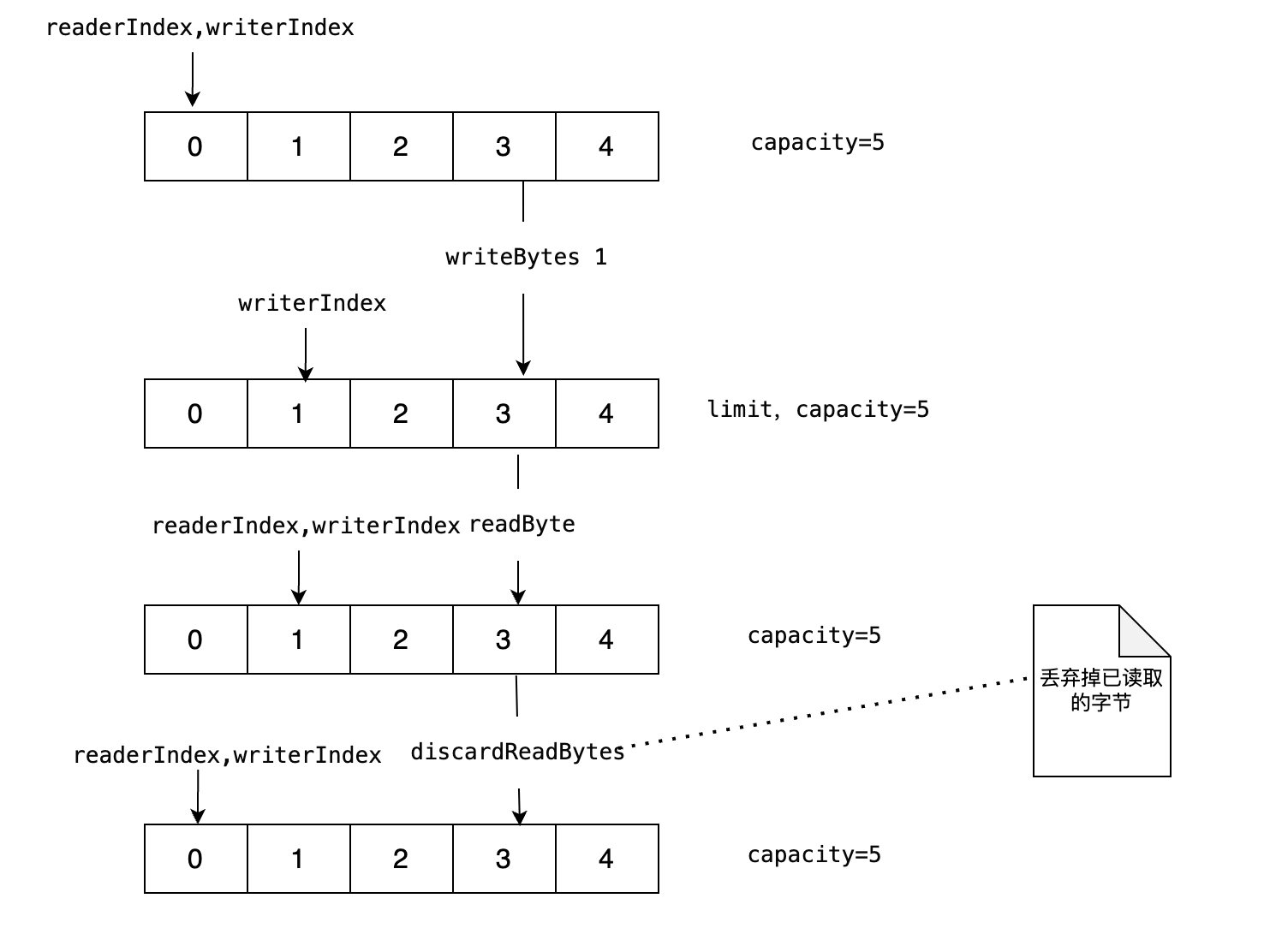
4.ByteBuf
public static void main(String[] args) {
// 创建一个大小为 5 ByteBuf
ByteBuf buf = Unpooled.buffer(5);
// 写入数据
buf.writeBytes(new byte[]{1,3,3});
// 读取数据
if (buf.isReadable()) {
System.out.println(buf.readByte());
}
buf.discardReadBytes();
buf.writeBytes(new byte[]{2});
// 释放资源
buf.release();
}
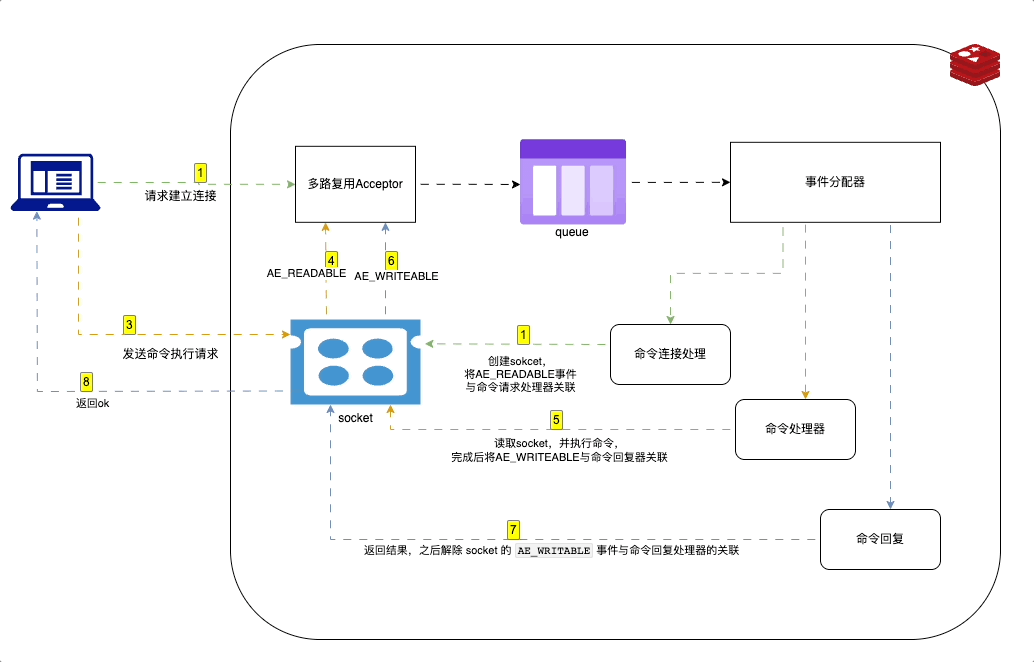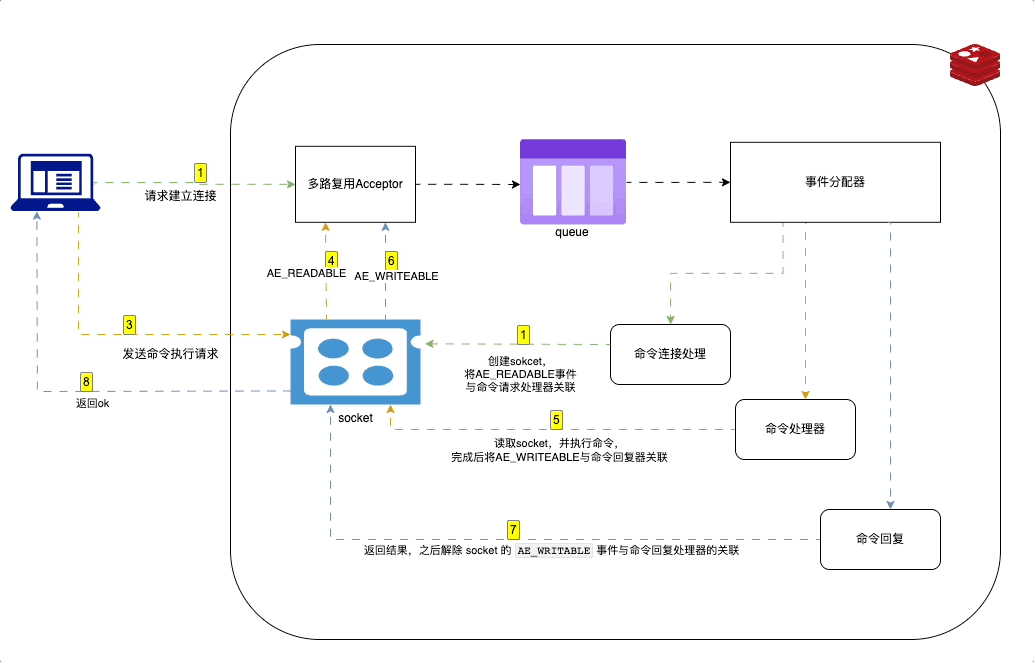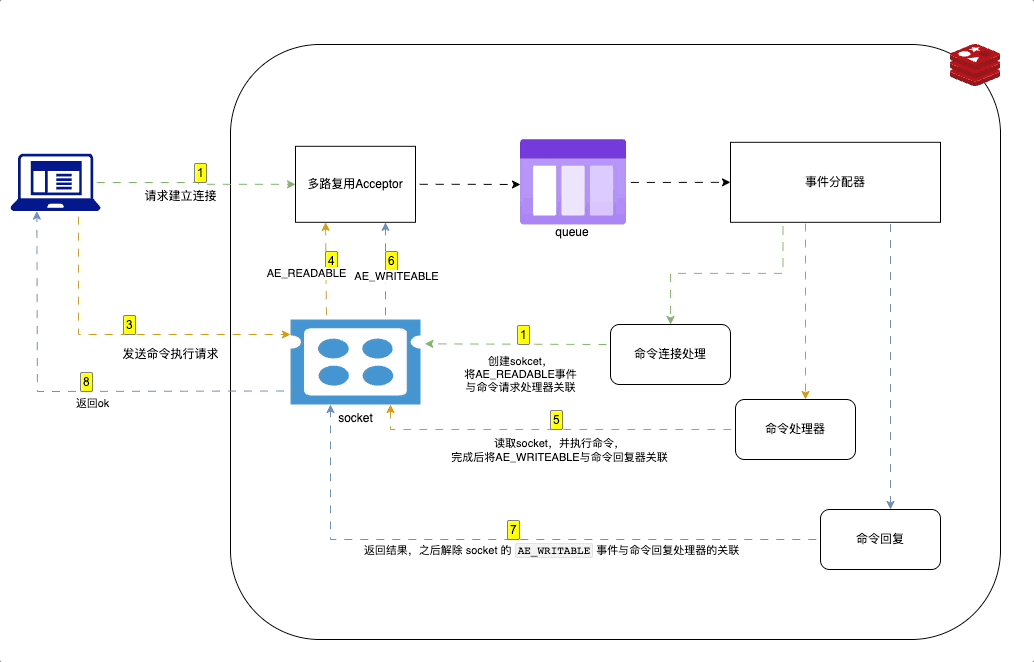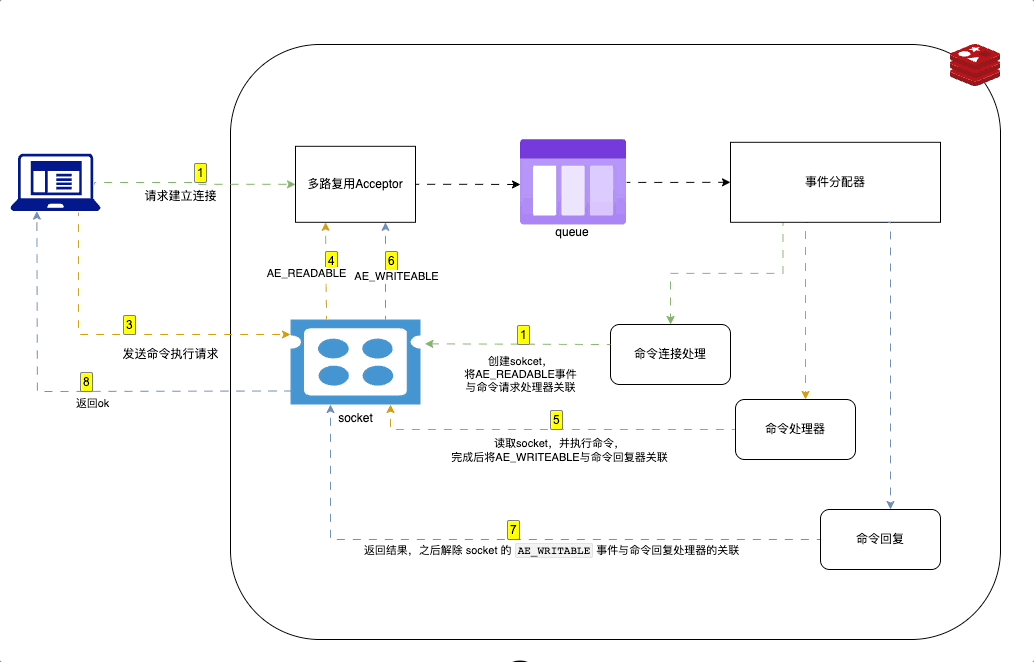
Redis事件驱动
概述
Redis 中使用事件驱动模型来处理客户端请求和服务器响应。采用 I/O 多路复用技术。
在 Redis 中,事件驱动的工作原理如下:
- Redis 服务器初始化一个事件循环,并在其中监听套接字描述符的 I/O 事件。
- 当有新的客户端连接请求时,server socket 会产生一个
AE_READABLE事件,并将其放入到队列中。 - 命令连接处理器创建socket连接,并将AE_READABLE事件与命令请求处理器关联。
- 客户段发送命令请求,产生可读事件,事件循环监听到之后压入队列,事件分配器发送给命令请求处理器。读取socket内容,执行命令,完成后将AE_WRITEABLE事件与命令回复器关联
- 如果客户端以准备好接收结果,socket会产生AE_WRITEABLE事件,然后继续压入队列,被命令回复处理器 处理 并返回结果。
Redis Pub/Sub
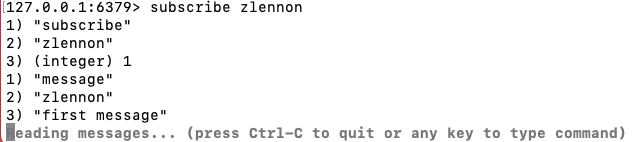
SUBSCRIBE,UNSUBSCRIBE 和 PUBLISH 实现了发布/订阅消息范式,其中发送者(发布者)不会直接发送消息给特定的接收者(订阅者)。相反,发布的消息被归类到通道(Channel)中,发布者并不知道是否有订阅者。订阅者对一个或多个通道表达兴趣,并且只接收感兴趣的消息,不知道是否有发布者。
1.基本的发布订阅

2.模式匹配


3. 取消订阅
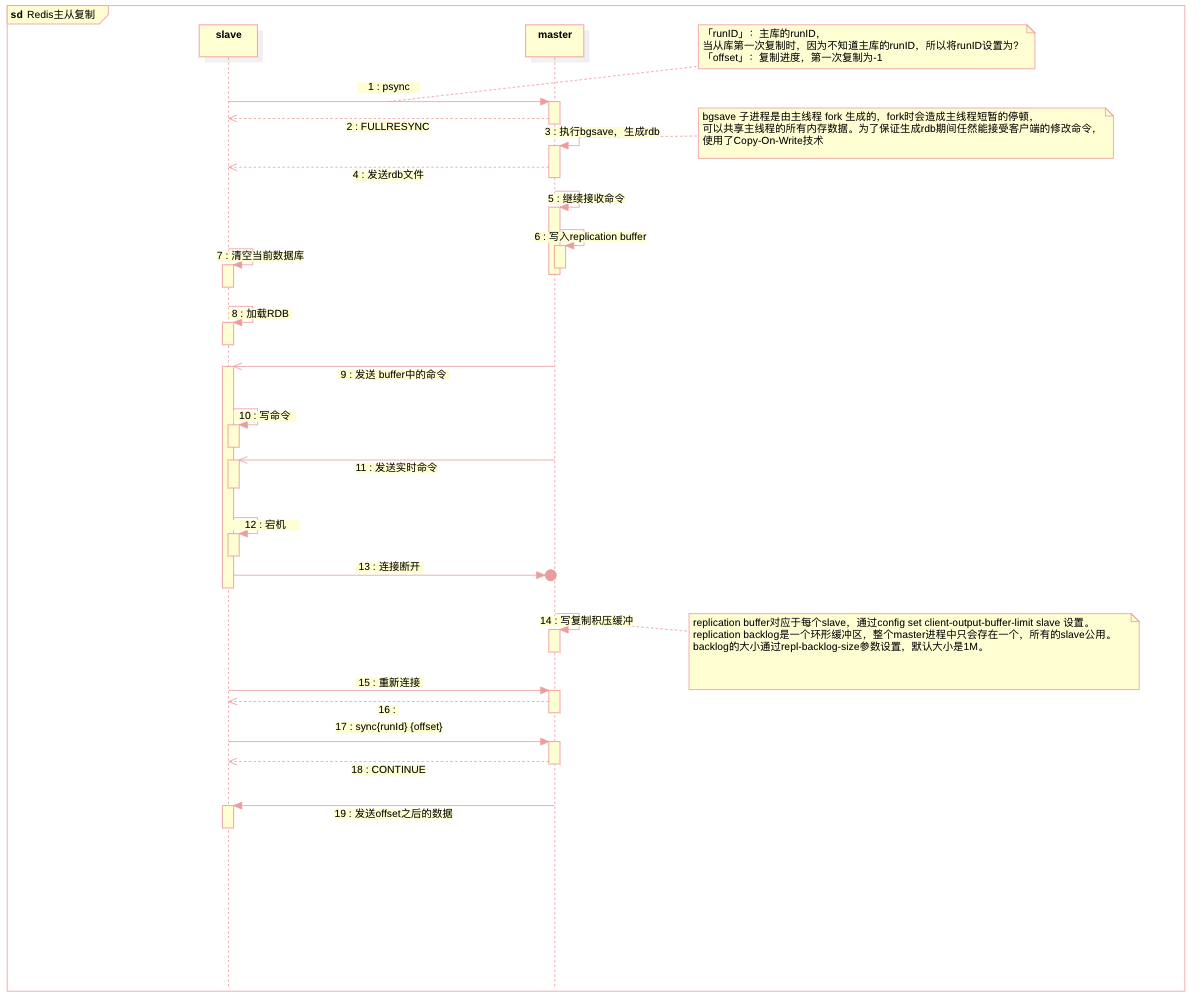
主从复制
Redis主进程fork生成的子进程可以共享主进程的所有内存数据,fork并不会带来明显的性能开销,因为不会立刻对内存进行拷贝,它会将拷贝内存的动作推迟到真正需要的时候。 如果主进程是读取内存数据,那么和BGSAVE子进程并不冲突。如果主进程要修改Redis内存中某个数据,那么操作系统内核会将被修改的内存数据复制一份(复制的是修改之前的数据),未被修改的内存数据依然被父子两个进程共享,被主进程修改的内存空间归属于主进程,被复制出来的原始数据归属于子进程。如此一来,主进程就可以在快照发生的过程中肆无忌惮地接受数据写入的请求,bgsave完成之后将新写的数据也写进rdb文件
redis server会为每一个连接到自己的客户端创建一个replication buffer,用来缓存主库执行的命令。等从库加载完成RDB文件后,主库就会把缓存的命令发送给从库
i/o多路复用程序的实现
redis的i/o复用程序底层实现了select,epoll,evport和kqueue这些i/o多路复用函数库,他们实现了相同的api,所以底层实现可以互换(工厂模式)。
select
在调用select函数时,应用程序会将需要监视的文件描述符集合传递给内核。内核会遍历这些文件描述符,检查它们的状态是否发生变化(如是否可以读取、是否可以写入等)。如果有文件描述符的状态发生变化,内核会将这些文件描述符添加到就绪列表中,然后返回给应用程序。
epoll
epoll使用了事件就绪通知机制。应用程序通过调用epoll_ctl函数向内核注册需要监视的文件描述符,并指定感兴趣的事件类型(如可读、可写等)。当有文件描述符的状态发生变化时,内核会立即将这些事件通知给应用程序,而不需要应用程序轮询文件描述符的状态。
evport
kqueue
Redis数据类型
主要提供了5种数据类型:字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(zset)。Redis还提供了Bitmap、HyperLogLog、Geo类型,但这些类型都是基于上述核心数据类型实现的。5.0版本中,Redis新增加了Streams数据类型,它是一个功能强大的、支持多播的、可持久化的消息队列。
1. string可以存储字符串、数字和二进制数据,除了值可以是String以外,所有的键也可以是string,string最大可以存储大小为512M的数据。
2. list保证数据线性有序且元素可重复,它支持lpush、blpush、rpop、brpop等操作,可以当作简单的消息队列使用,一个list最多可以存储2^32-1个元素。
3. hash的值本身也是一个键值对结构,最多能存储2^32-1个元素。
4. set是无序不可重复的,它支持多个set求交集、并集、差集,适合实现共同关注之类的需求,一个set最多可以存储2^32-1个元素。
5. zset是有序不可重复的,它通过给每个元素设置一个分数来作为排序的依据,一个zset最多可以存储2^32-1个元素。
每种类型支持多个编码,每一种编码采取一个特殊的结构来实现,各类数据结构内部的编码及结构:
- string:编码分为int、raw、embstr。int底层实现为long,当数据为整数型并且可以用long类型表示时可以用long存储。embstr底层实现为占一块内存的SDS结构,当数据为长度不超过32字节的字符串时,选择以此结构连续存储元数据和值。raw底层实现为占两块内存的SDS,用于存储长度超过32字节的字符串数据,此时会在两块内存中分别存储元数据和值。
- list:编码分为ziplist、linkedlist、quicklist(3.2以前版本没有quicklist)。ziplist底层实现为压缩列表,当元素数量小于512且所有元素长度都小于64字节时,使用这种结构来存储。linkedlist底层实现为双端链表,当数据不符合ziplist条件时,使用这种结构存储。3.2版本之后list采用quicklist的快速列表结构来代替前两种。
- hash:编码分为ziplist、hashtable两种。其中ziplist底层实现为压缩列表,当键值对数量小于512,并且所有的键值长度都小于64字节时使用这种结构进行存储。hashtable底层实现为字典,当不符合压缩列表存储条件时,使用字典进行存储。
- set:编码分为inset、hashtable。intset底层实现为整数集合,当所有元素都是整数值且数量不超过512个时使用该结构存储,否则使用字典结构存储。
- zset:编码分为ziplist、skiplist。当元素数量小于128,并且每个元素长度都小于64字节时,使用ziplist压缩列表结构存储,否则使用skiplist的字典+跳表的结构存储。
Redis没有直接使用C语言传统的字符串表示,而是自己构建了一种名为简单动态字符串(Simple Dynamic String),即SDS的抽象类型,并将SDS用作Redis的默认字符串表示。每个sds.h/sdshdr结构表示一个SDS值,它有三个属性,这里我们举个例子:

<di>
· len属性值为5,代表这个SDS存了一个五字节长的字符串;
· buf属性是一个char类型的数组,数组的前五个字节分别保存了‘H’、‘e’、‘l’、‘l’、‘o’ 五个字符,而最后一个字节则保存了空字符‘’。
SDS遵循C字符串以空字符结尾的惯例,保存空字符的一字节空间不计算在SDS的len属性中。为空字符串分配1字节的额外空间以及添加空字符到字符串末尾等操作都是由SDS函数自动完成的,所以这个空字符串对于SDS的使用者来说完全透明。遵循空字符串的好处是,SDS可以直接重用一部分C字符串函数库里的函数。
</di>
AMQP
RabbitMQ
1.概述

2.RabbitMQ四种类型交换机
direct
Direct 类型的交换器会把消息路由到那些 BindingKey 和 RoutingKey 完全匹配的队列中。这是一个完整的匹配,所谓完整匹配,是指路由键需要和绑定键一模一样
Topic
模糊匹配交换器,routing key可以多变。只要发送消息时指定的routing key符合交换机与队列绑定的binding key的匹配规则,则消息可以被正确投递到指定队列。
# :代表匹配一个多或多个、或者一个也匹配不到,支持多级
* :代表必须匹配一个,且只能是一级
Fanout
消息广播的模式,即将消息广播到所有绑定到它的队列中,而不考虑 RoutingKey 的值,如果设置了 RoutingKey ,则 RoutingKey 依然被忽略。
Headers
headers类型的交换机在绑定队列时需要指定参数Arguments,发送消息时需要指定headers和Arguments相匹配,消息才能被投递到对应的队列中。
3.相关文章
Kafka
总览
消费者offset日志提交
消费者会将提交日志写入__consumer_offsets主题,以下是该主题的消息类容
goffset是消费者组,cat-offset-topic是topic,0是分区

分区日志
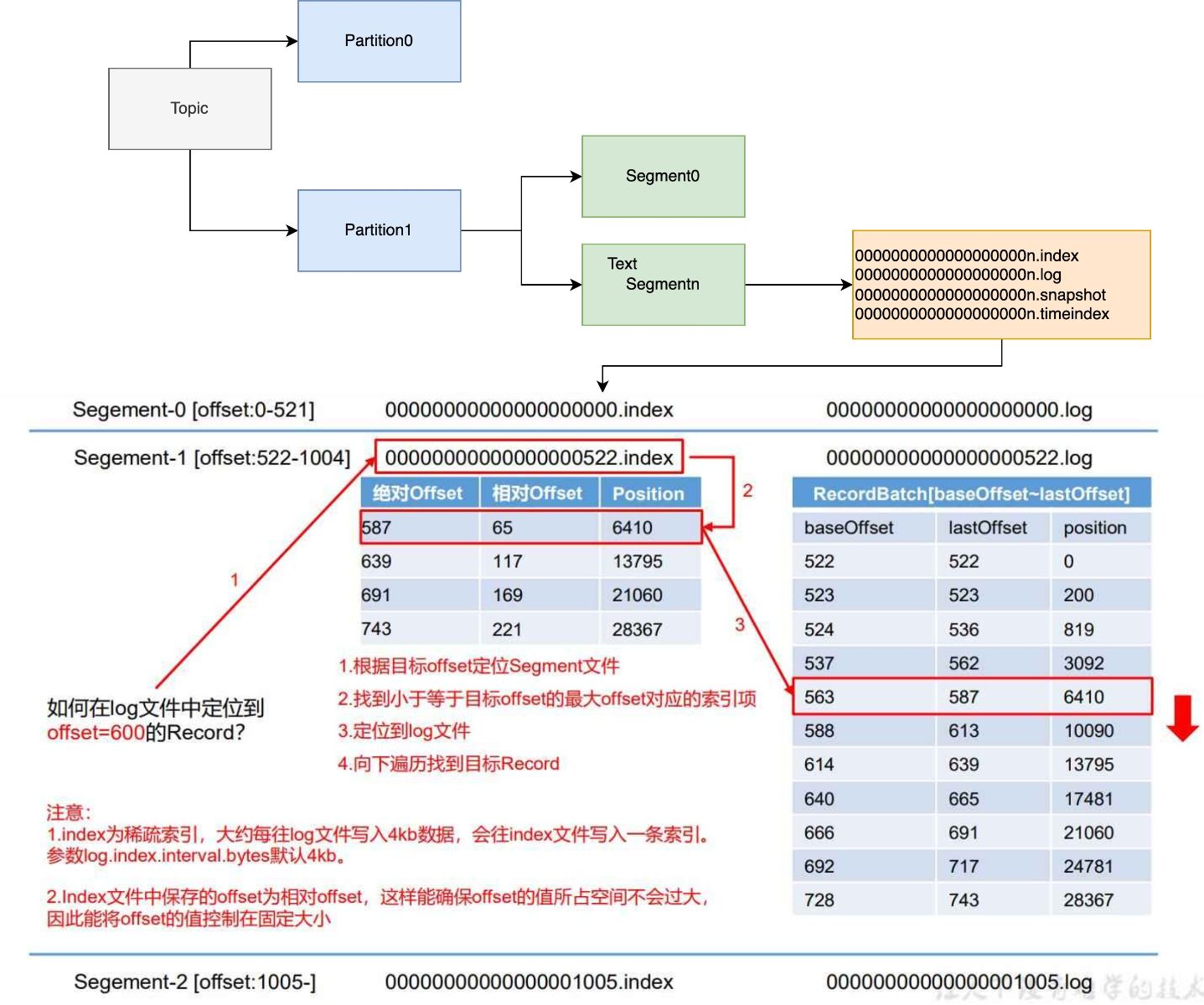
Log starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: 0 lastSequence: 0 producerId: 2 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 170n3993062n6 size: 83 magic: 2 compresscodec: none crc: 380106178n isvalid: true
baseOffset: 1 lastOffset: 1 count: 1 baseSequence: 0 lastSequence: 0 producerId: 4 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 83 CreateTime: 170n399629067 size: 83 magic: 2 compresscodec: none crc: 230271771n isvalid: true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 1 lastSequence: 1 producerId: 4 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 166 CreateTime: 170n399629693 size: 83 magic: 2 compresscodec: none crc: 70082811 isvalid: true
baseOffset和lastOffset表示消息的偏移量范围。baseSequence和lastSequence表示消息的序列号范围。producerId是生产者的唯一标识。producerEpoch是生产者的纪元。partitionLeaderEpoch是分区领导者的纪元。isTransactional表示消息是否是事务性消息。isControl表示消息是否是控制消息。deleteHorizonMs表示消息删除的时间戳。position表示消息在日志中的位置。CreateTime表示消息的创建时间。size表示消息的大小。magic表示消息的版本。compresscodec表示消息的压缩编解码方式。crc是消息的循环冗余校验。isvalid表示消息是否有效。
控制器(Controller)
在 Kafka 集群中,其中一个broker充当控制器,负责管理分区和副本的状态,并执行重新分配分区等管理任务。
1.kraft模式
kraft模式中一个一个broker可以作为单个borker或controller,或者同时充当两种角色
2.zookeeper模式
zookeeper模式下boker启动时会想zk注册零时结点,第一个成功创建/controller的将成为controller
Kafka为什么快
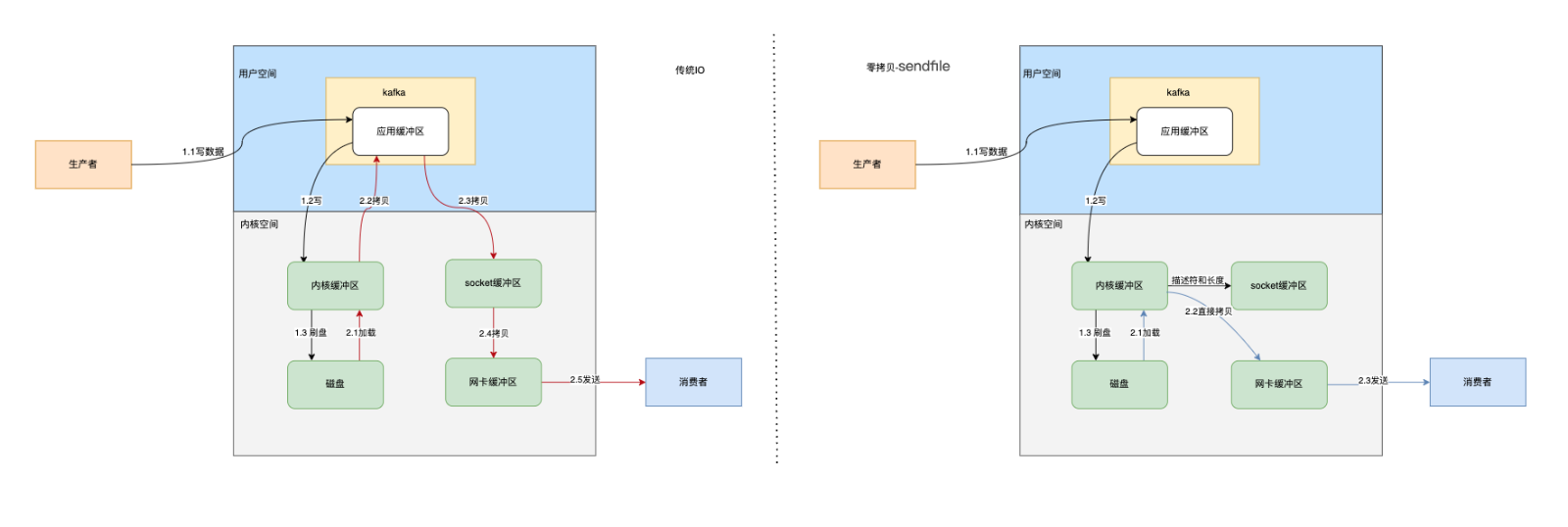
kafka快的一个原因是使用了零拷贝技术