申明
本文使用授权协议 Creative Commons Attribution-ShareAlike 4.0 International License。命令整理来源网络与命令行工具。
命令行的艺术
前言
涵盖范围:
- 这篇文章不仅能帮助刚接触命令行的新手,而且对具有经验的人也大有裨益。本文致力于做到覆盖面广(涉及所有重要的内容),具体(给出具体的最常用的例子),以及简洁(避免冗余的内容,或是可以在其他地方轻松查到的细枝末节)。在特定应用场景下,本文的内容属于基本功或者能帮助您节约大量的时间。
- 本文主要为 Linux 所写,但在仅限 OS X 系统章节和仅限 Windows 系统章节中也包含有对应操作系统的内容。除去这两个章节外,其它的内容大部分均可在其他类 Unix 系统或 OS X,甚至 Cygwin 中得到应用。
- 本文主要关注于交互式 Bash,但也有很多技巧可以应用于其他 shell 和 Bash 脚本当中。
- 除去“标准的”Unix 命令,本文还包括了一些依赖于特定软件包的命令(前提是它们具有足够的价值)。
注意事项:
- 为了能在一页内展示尽量多的东西,一些具体的信息可以在引用的页面中找到。我们相信机智的你知道如何使用 Google 或者其他搜索引擎来查阅到更多的详细信息。文中部分命令需要您使用
apt-get,yum,dnf,pacman,pip或brew(以及其它合适的包管理器)来安装依赖的程序。 - 遇到问题的话,请尝试使用 Explainshell 去获取相关命令、参数、管道等内容的解释。
基础
-
学习 Bash 的基础知识。具体地,在命令行中输入
man bash并至少全文浏览一遍; 它理解起来很简单并且不冗长。其他的 shell 可能很好用,但 Bash 的功能已经足够强大并且到几乎总是可用的( 如果你只学习 zsh,fish 或其他的 shell 的话,在你自己的设备上会显得很方便,但过度依赖这些功能会给您带来不便,例如当你需要在服务器上工作时)。 -
熟悉至少一个基于文本的编辑器。通常而言 Vim (
vi) 会是你最好的选择,毕竟在终端中编辑文本时 Vim 是最好用的工具(甚至大部分情况下 Vim 要比 Emacs、大型 IDE 或是炫酷的编辑器更好用)。 -
学会如何使用
man命令去阅读文档。学会使用apropos去查找文档。知道有些命令并不对应可执行文件,而是在 Bash 内置好的,此时可以使用help和help -d命令获取帮助信息。你可以用type 命令来判断这个命令到底是可执行文件、shell 内置命令还是别名。 -
学会使用
>和<来重定向输出和输入,学会使用|来重定向管道。明白>会覆盖了输出文件而>>是在文件末添加。了解标准输出 stdout 和标准错误 stderr。 -
学会使用通配符
*(或许再算上?和[...]) 和引用以及引用中'和"的区别(后文中有一些具体的例子)。 -
熟悉 Bash 中的任务管理工具:
&,ctrl-z,ctrl-c,jobs,fg,bg,kill等。 -
学会使用
ssh进行远程命令行登录,最好知道如何使用ssh-agent,ssh-add等命令来实现基础的无密码认证登录。 -
学会基本的文件管理工具:
ls和ls -l(了解ls -l中每一列代表的意义),less,head,tail和tail -f(甚至less +F),ln和ln -s(了解硬链接与软链接的区别),chown,chmod,du(硬盘使用情况概述:du -hs *)。 关于文件系统的管理,学习df,mount,fdisk,mkfs,lsblk。知道 inode 是什么(与ls -i和df -i等命令相关)。 -
学习基本的网络管理工具:
ip或ifconfig,dig。 -
学习并使用一种版本控制管理系统,例如
git。 -
熟悉正则表达式,学会使用
grep/egrep,它们的参数中-i,-o,-v,-A,-B和-C这些是很常用并值得认真学习的。 -
学会使用
apt-get,yum,dnf或pacman(具体使用哪个取决于你使用的 Linux 发行版)来查找和安装软件包。并确保你的环境中有pip来安装基于 Python 的命令行工具 (接下来提到的部分程序使用pip来安装会很方便)。
日常使用
-
在 Bash 中,可以通过按 Tab 键实现自动补全参数,使用 ctrl-r 搜索命令行历史记录(按下按键之后,输入关键字便可以搜索,重复按下 ctrl-r 会向后查找匹配项,按下 Enter 键会执行当前匹配的命令,而按下右方向键会将匹配项放入当前行中,不会直接执行,以便做出修改)。
-
在 Bash 中,可以按下 ctrl-w 删除你键入的最后一个单词,ctrl-u 可以删除行内光标所在位置之前的内容,alt-b 和 alt-f 可以以单词为单位移动光标,ctrl-a 可以将光标移至行首,ctrl-e 可以将光标移至行尾,ctrl-k 可以删除光标至行尾的所有内容,ctrl-l 可以清屏。键入
man readline可以查看 Bash 中的默认快捷键。内容有很多,例如 alt-. 循环地移向前一个参数,而 alt-* 可以展开通配符。 -
你喜欢的话,可以执行
set -o vi来使用 vi 风格的快捷键,而执行set -o emacs可以把它改回来。 -
为了便于编辑长命令,在设置你的默认编辑器后(例如
export EDITOR=vim),ctrl-x ctrl-e 会打开一个编辑器来编辑当前输入的命令。在 vi 风格下快捷键则是 escape-v。 -
键入
history查看命令行历史记录,再用!n(n是命令编号)就可以再次执行。其中有许多缩写,最有用的大概就是!$, 它用于指代上次键入的参数,而!!可以指代上次键入的命令了(参考 man 页面中的“HISTORY EXPANSION”)。不过这些功能,你也可以通过快捷键 ctrl-r 和 alt-. 来实现。 -
cd命令可以切换工作路径,输入cd ~可以进入 home 目录。要访问你的 home 目录中的文件,可以使用前缀~(例如~/.bashrc)。在sh脚本里则用环境变量$HOME指代 home 目录的路径。 -
回到前一个工作路径:
cd -。 -
如果你输入命令的时候中途改了主意,按下 alt-# 在行首添加
#把它当做注释再按下回车执行(或者依次按下 ctrl-a, #, enter)。这样做的话,之后借助命令行历史记录,你可以很方便恢复你刚才输入到一半的命令。 -
使用
xargs( 或parallel)。他们非常给力。注意到你可以控制每行参数个数(-L)和最大并行数(-P)。如果你不确定它们是否会按你想的那样工作,先使用xargs echo查看一下。此外,使用-I{}会很方便。例如:
find . -name '*.py' | xargs grep some_function
cat hosts | xargs -I{} ssh root@{} hostname
-
pstree -p以一种优雅的方式展示进程树。 -
使用
pgrep和pkill根据名字查找进程或发送信号(-f参数通常有用)。 -
了解你可以发往进程的信号的种类。比如,使用
kill -STOP [pid]停止一个进程。使用man 7 signal查看详细列表。 -
使用
nohup或disown使一个后台进程持续运行。 -
使用
netstat -lntp或ss -plat检查哪些进程在监听端口(默认是检查 TCP 端口; 添加参数-u则检查 UDP 端口)或者lsof -iTCP -sTCP:LISTEN -P -n(这也可以在 OS X 上运行)。 -
lsof来查看开启的套接字和文件。 -
使用
uptime或w来查看系统已经运行多长时间。 -
使用
alias来创建常用命令的快捷形式。例如:alias ll='ls -latr'创建了一个新的命令别名ll。 -
可以把别名、shell 选项和常用函数保存在
~/.bashrc,具体看下这篇文章。这样做的话你就可以在所有 shell 会话中使用你的设定。 -
把环境变量的设定以及登陆时要执行的命令保存在
~/.bash_profile。而对于从图形界面启动的 shell 和cron启动的 shell,则需要单独配置文件。 -
要想在几台电脑中同步你的配置文件(例如
.bashrc和.bash_profile),可以借助 Git。 -
当变量和文件名中包含空格的时候要格外小心。Bash 变量要用引号括起来,比如
"$FOO"。尽量使用-0或-print0选项以便用 NULL 来分隔文件名,例如locate -0 pattern | xargs -0 ls -al或find / -print0 -type d | xargs -0 ls -al。如果 for 循环中循环访问的文件名含有空字符(空格、tab 等字符),只需用IFS=$'\n'把内部字段分隔符设为换行符。 -
在 Bash 脚本中,使用
set -x去调试输出(或者使用它的变体set -v,它会记录原始输入,包括多余的参数和注释)。尽可能地使用严格模式:使用set -e令脚本在发生错误时退出而不是继续运行;使用set -u来检查是否使用了未赋值的变量;试试set -o pipefail,它可以监测管道中的错误。当牵扯到很多脚本时,使用trap来检测 ERR 和 EXIT。一个好的习惯是在脚本文件开头这样写,这会使它能够检测一些错误,并在错误发生时中断程序并输出信息:
set -euo pipefail
trap "echo 'error: Script failed: see failed command above'" ERR
- 在 Bash 脚本中,子 shell(使用括号
(...))是一种组织参数的便捷方式。一个常见的例子是临时地移动工作路径,代码如下:
# do something in current dir
(cd /some/other/dir && other-command)
# continue in original dir
-
在 Bash 中,变量有许多的扩展方式。
${name:?error message}用于检查变量是否存在。此外,当 Bash 脚本只需要一个参数时,可以使用这样的代码input_file=${1:?usage: $0 input_file}。在变量为空时使用默认值:${name:-default}。如果你要在之前的例子中再加一个(可选的)参数,可以使用类似这样的代码output_file=${2:-logfile},如果省略了 $2,它的值就为空,于是output_file就会被设为logfile。数学表达式:i=$(( (i + 1) % 5 ))。序列:{1..10}。截断字符串:${var%suffix}和${var#prefix}。例如,假设var=foo.pdf,那么echo ${var%.pdf}.txt将输出foo.txt。 -
使用括号扩展(
{...})来减少输入相似文本,并自动化文本组合。这在某些情况下会很有用,例如mv foo.{txt,pdf} some-dir(同时移动两个文件),cp somefile{,.bak}(会被扩展成cp somefile somefile.bak)或者mkdir -p test-{a,b,c}/subtest-{1,2,3}(会被扩展成所有可能的组合,并创建一个目录树)。 -
通过使用
<(some command)可以将输出视为文件。例如,对比本地文件/etc/hosts和一个远程文件:
diff /etc/hosts <(ssh somehost cat /etc/hosts)
- 编写脚本时,你可能会想要把代码都放在大括号里。缺少右括号的话,代码就会因为语法错误而无法执行。如果你的脚本是要放在网上分享供他人使用的,这样的写法就体现出它的好处了,因为这样可以防止下载不完全代码被执行。
{
# 在这里写代码
}
-
了解 Bash 中的“here documents”,例如
cat <<EOF ...。 -
在 Bash 中,同时重定向标准输出和标准错误:
some-command >logfile 2>&1或者some-command &>logfile。通常,为了保证命令不会在标准输入里残留一个未关闭的文件句柄捆绑在你当前所在的终端上,在命令后添加</dev/null是一个好习惯。 -
使用
man ascii查看具有十六进制和十进制值的ASCII表。man unicode,man utf-8,以及man latin1有助于你去了解通用的编码信息。 -
使用
screen或tmux来使用多份屏幕,当你在使用 ssh 时(保存 session 信息)将尤为有用。而byobu可以为它们提供更多的信息和易用的管理工具。另一个轻量级的 session 持久化解决方案是dtach。 -
ssh 中,了解如何使用
-L或-D(偶尔需要用-R)开启隧道是非常有用的,比如当你需要从一台远程服务器上访问 web 页面。 -
对 ssh 设置做一些小优化可能是很有用的,例如这个
~/.ssh/config文件包含了防止特定网络环境下连接断开、压缩数据、多通道等选项:
TCPKeepAlive=yes
ServerAliveInterval=15
ServerAliveCountMax=6
Compression=yes
ControlMaster auto
ControlPath /tmp/%r@%h:%p
ControlPersist yes
-
一些其他的关于 ssh 的选项是与安全相关的,应当小心翼翼的使用。例如你应当只能在可信任的网络中启用
StrictHostKeyChecking=no,ForwardAgent=yes。 -
考虑使用
mosh作为 ssh 的替代品,它使用 UDP 协议。它可以避免连接被中断并且对带宽需求更小,但它需要在服务端做相应的配置。 -
获取八进制形式的文件访问权限(修改系统设置时通常需要,但
ls的功能不那么好用并且通常会搞砸),可以使用类似如下的代码:
stat -c '%A %a %n' /etc/timezone
-
使用
fpp(PathPicker)可以与基于另一个命令(例如git)输出的文件交互。 -
将 web 服务器上当前目录下所有的文件(以及子目录)暴露给你所处网络的所有用户,使用:
python -m SimpleHTTPServer 7777(使用端口 7777 和 Python 2)或python -m http.server 7777(使用端口 7777 和 Python 3)。 -
以其他用户的身份执行命令,使用
sudo。默认以 root 用户的身份执行;使用-u来指定其他用户。使用-i来以该用户登录(需要输入_你自己的_密码)。 -
将 shell 切换为其他用户,使用
su username或者sudo - username。加入-会使得切换后的环境与使用该用户登录后的环境相同。省略用户名则默认为 root。切换到哪个用户,就需要输入_哪个用户的_密码。 -
了解命令行的 128K 限制。使用通配符匹配大量文件名时,常会遇到“Argument list too long”的错误信息。(这种情况下换用
find或xargs通常可以解决。) -
当你需要一个基本的计算器时,可以使用
python解释器(当然你要用 python 的时候也是这样)。例如:
>>> 2+3
5
文件及数据处理
-
在当前目录下通过文件名查找一个文件,使用类似于这样的命令:
find . -iname '*something*'。在所有路径下通过文件名查找文件,使用locate something(但注意到updatedb可能没有对最近新建的文件建立索引,所以你可能无法定位到这些未被索引的文件)。 -
使用
ag在源代码或数据文件里检索(grep -r同样可以做到,但相比之下ag更加先进)。 -
将 HTML 转为文本:
lynx -dump -stdin。 -
Markdown,HTML,以及所有文档格式之间的转换,试试
pandoc。 -
当你要处理棘手的 XML 时候,
xmlstarlet算是上古时代流传下来的神器。 -
使用
jq处理 JSON。 -
使用
shyaml处理 YAML。 -
要处理 Excel 或 CSV 文件的话,csvkit 提供了
in2csv,csvcut,csvjoin,csvgrep等方便易用的工具。 -
当你要处理 Amazon S3 相关的工作的时候,
s3cmd是一个很方便的工具而s4cmd的效率更高。Amazon 官方提供的aws以及saws是其他 AWS 相关工作的基础,值得学习。 -
了解如何使用
sort和uniq,包括 uniq 的-u参数和-d参数,具体内容在后文单行脚本节中。另外可以了解一下comm。 -
了解如何使用
cut,paste和join来更改文件。很多人都会使用cut,但遗忘了join。 -
了解如何运用
wc去计算新行数(-l),字符数(-m),单词数(-w)以及字节数(-c)。 -
了解如何使用
tee将标准输入复制到文件甚至标准输出,例如ls -al | tee file.txt。 -
要进行一些复杂的计算,比如分组、逆序和一些其他的统计分析,可以考虑使用
datamash。 -
注意到语言设置(中文或英文等)对许多命令行工具有一些微妙的影响,比如排序的顺序和性能。大多数 Linux 的安装过程会将
LANG或其他有关的变量设置为符合本地的设置。要意识到当你改变语言设置时,排序的结果可能会改变。明白国际化可能会使 sort 或其他命令运行效率下降许多倍。某些情况下(例如集合运算)你可以放心的使用export LC_ALL=C来忽略掉国际化并按照字节来判断顺序。 -
你可以单独指定某一条命令的环境,只需在调用时把环境变量设定放在命令的前面,例如
TZ=Pacific/Fiji date可以获取斐济的时间。 -
了解如何使用
awk和sed来进行简单的数据处理。 参阅 One-liners 获取示例。 -
替换一个或多个文件中出现的字符串:
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
- 使用
repren来批量重命名文件,或是在多个文件中搜索替换内容。(有些时候rename命令也可以批量重命名,但要注意,它在不同 Linux 发行版中的功能并不完全一样。)
# 将文件、目录和内容全部重命名 foo -> bar:
repren --full --preserve-case --from foo --to bar .
# 还原所有备份文件 whatever.bak -> whatever:
repren --renames --from '(.*)\.bak' --to '\1' *.bak
# 用 rename 实现上述功能(若可用):
rename 's/\.bak$//' *.bak
- 根据 man 页面的描述,
rsync是一个快速且非常灵活的文件复制工具。它闻名于设备之间的文件同步,但其实它在本地情况下也同样有用。在安全设置允许下,用rsync代替scp可以实现文件续传,而不用重新从头开始。它同时也是删除大量文件的最快方法之一:
mkdir empty && rsync -r --delete empty/ some-dir && rmdir some-dir
-
若要在复制文件时获取当前进度,可使用
pv,pycp,progress,rsync --progress。若所执行的复制为block块拷贝,可以使用dd status=progress。 -
使用
shuf可以以行为单位来打乱文件的内容或从一个文件中随机选取多行。 -
了解
sort的参数。显示数字时,使用-n或者-h来显示更易读的数(例如du -h的输出)。明白排序时关键字的工作原理(-t和-k)。例如,注意到你需要-k1,1来仅按第一个域来排序,而-k1意味着按整行排序。稳定排序(sort -s)在某些情况下很有用。例如,以第二个域为主关键字,第一个域为次关键字进行排序,你可以使用sort -k1,1 | sort -s -k2,2。 -
如果你想在 Bash 命令行中写 tab 制表符,按下 ctrl-v [Tab] 或键入
$'\t'(后者可能更好,因为你可以复制粘贴它)。 -
标准的源代码对比及合并工具是
diff和patch。使用diffstat查看变更总览数据。注意到diff -r对整个文件夹有效。使用diff -r tree1 tree2 | diffstat查看变更的统计数据。vimdiff用于比对并编辑文件。 -
对于二进制文件,使用
hd,hexdump或者xxd使其以十六进制显示,使用bvi,hexedit或者biew来进行二进制编辑。 -
同样对于二进制文件,
strings(包括grep等工具)可以帮助在二进制文件中查找特定比特。 -
制作二进制差分文件(Delta 压缩),使用
xdelta3。 -
使用
iconv更改文本编码。需要更高级的功能,可以使用uconv,它支持一些高级的 Unicode 功能。例如,这条命令移除了所有重音符号:
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
-
拆分文件可以使用
split(按大小拆分)和csplit(按模式拆分)。 -
操作日期和时间表达式,可以用
dateutils中的dateadd、datediff、strptime等工具。 -
使用
zless、zmore、zcat和zgrep对压缩过的文件进行操作。 -
文件属性可以通过
chattr进行设置,它比文件权限更加底层。例如,为了保护文件不被意外删除,可以使用不可修改标记:sudo chattr +i /critical/directory/or/file -
使用
getfacl和setfacl以保存和恢复文件权限。例如:
getfacl -R /some/path > permissions.txt
setfacl --restore=permissions.txt
- 为了高效地创建空文件,请使用
truncate(创建稀疏文件),fallocate(用于 ext4,xfs,btrf 和 ocfs2 文件系统),xfs_mkfile(适用于几乎所有的文件系统,包含在 xfsprogs 包中),mkfile(用于类 Unix 操作系统,比如 Solaris 和 Mac OS)。
系统调试
-
curl和curl -I可以被轻松地应用于 web 调试中,它们的好兄弟wget也是如此,或者也可以试试更潮的httpie。 -
获取 CPU 和硬盘的使用状态,通常使用使用
top(htop更佳),iostat和iotop。而iostat -mxz 15可以让你获悉 CPU 和每个硬盘分区的基本信息和性能表现。 -
使用
netstat和ss查看网络连接的细节。 -
dstat在你想要对系统的现状有一个粗略的认识时是非常有用的。然而若要对系统有一个深度的总体认识,使用glances,它会在一个终端窗口中向你提供一些系统级的数据。 -
若要了解内存状态,运行并理解
free和vmstat的输出。值得留意的是“cached”的值,它指的是 Linux 内核用来作为文件缓存的内存大小,而与空闲内存无关。 -
Java 系统调试则是一件截然不同的事,一个可以用于 Oracle 的 JVM 或其他 JVM 上的调试的技巧是你可以运行
kill -3 <pid>同时一个完整的栈轨迹和堆概述(包括 GC 的细节)会被保存到标准错误或是日志文件。JDK 中的jps,jstat,jstack,jmap很有用。SJK tools 更高级。 -
使用
mtr去跟踪路由,用于确定网络问题。 -
用
ncdu来查看磁盘使用情况,它比寻常的命令,如du -sh *,更节省时间。 -
ab工具(Apache 中自带)可以简单粗暴地检查 web 服务器的性能。对于更复杂的负载测试,使用siege。 -
了解
strace和ltrace。这俩工具在你的程序运行失败、挂起甚至崩溃,而你却不知道为什么或你想对性能有个总体的认识的时候是非常有用的。注意 profile 参数(-c)和附加到一个运行的进程参数 (-p)。 -
了解使用
ldd来检查共享库。但是永远不要在不信任的文件上运行。 -
了解如何运用
gdb连接到一个运行着的进程并获取它的堆栈轨迹。 -
学会使用
/proc。它在调试正在出现的问题的时候有时会效果惊人。比如:/proc/cpuinfo,/proc/meminfo,/proc/cmdline,/proc/xxx/cwd,/proc/xxx/exe,/proc/xxx/fd/,/proc/xxx/smaps(这里的xxx表示进程的 id 或 pid)。 -
当调试一些之前出现的问题的时候,
sar非常有用。它展示了 cpu、内存以及网络等的历史数据。 -
查看你当前使用的系统,使用
uname,uname -a(Unix/kernel 信息)或者lsb_release -a(Linux 发行版信息)。 -
无论什么东西工作得很欢乐(可能是硬件或驱动问题)时可以试试
dmesg。 -
如果你删除了一个文件,但通过
du发现没有释放预期的磁盘空间,请检查文件是否被进程占用:lsof | grep deleted | grep "filename-of-my-big-file"
单行脚本
一些命令组合的例子:
- 当你需要对文本文件做集合交、并、差运算时,
sort和uniq会是你的好帮手。具体例子请参照代码后面的,此处假设a与b是两内容不同的文件。这种方式效率很高,并且在小文件和上 G 的文件上都能运用(注意尽管在/tmp在一个小的根分区上时你可能需要-T参数,但是实际上sort并不被内存大小约束),参阅前文中关于LC_ALL和sort的-u参数的部分。
sort a b | uniq > c # c 是 a 并 b
sort a b | uniq -d > c # c 是 a 交 b
sort a b b | uniq -u > c # c 是 a - b
-
使用
grep . *(每行都会附上文件名)或者head -100 *(每个文件有一个标题)来阅读检查目录下所有文件的内容。这在检查一个充满配置文件的目录(如/sys、/proc、/etc)时特别好用。 -
计算文本文件第三列中所有数的和(可能比同等作用的 Python 代码快三倍且代码量少三倍):
awk '{ x += $3 } END { print x }' myfile
- 如果你想在文件树上查看大小/日期,这可能看起来像递归版的
ls -l但比ls -lR更易于理解:
find . -type f -ls
- 假设你有一个类似于 web 服务器日志文件的文本文件,并且一个确定的值只会出现在某些行上,假设一个
acct_id参数在 URI 中。如果你想计算出每个acct_id值有多少次请求,使用如下代码:
egrep -o 'acct_id=[0-9]+' access.log | cut -d= -f2 | sort | uniq -c | sort -rn
-
要持续监测文件改动,可以使用
watch,例如检查某个文件夹中文件的改变,可以用watch -d -n 2 'ls -rtlh | tail';或者在排查 WiFi 设置故障时要监测网络设置的更改,可以用watch -d -n 2 ifconfig。 -
运行这个函数从这篇文档中随机获取一条技巧(解析 Markdown 文件并抽取项目):
function taocl() {
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README-zh.md|
pandoc -f markdown -t html |
iconv -f 'utf-8' -t 'unicode' |
xmlstarlet fo --html --dropdtd |
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
xmlstarlet unesc | fmt -80
}
冷门但有用
-
expr:计算表达式或正则匹配 -
m4:简单的宏处理器 -
yes:多次打印字符串 -
cal:漂亮的日历 -
env:执行一个命令(脚本文件中很有用) -
printenv:打印环境变量(调试时或在写脚本文件时很有用) -
look:查找以特定字符串开头的单词或行 -
cut,paste和join:数据修改 -
fmt:格式化文本段落 -
pr:将文本格式化成页/列形式 -
fold:包裹文本中的几行 -
column:将文本格式化成多个对齐、定宽的列或表格 -
expand和unexpand:制表符与空格之间转换 -
nl:添加行号 -
seq:打印数字 -
bc:计算器 -
factor:分解因数 -
gpg:加密并签名文件 -
toe:terminfo 入口列表 -
nc:网络调试及数据传输 -
socat:套接字代理,与netcat类似 -
slurm:网络流量可视化 -
dd:文件或设备间传输数据 -
file:确定文件类型 -
tree:以树的形式显示路径和文件,类似于递归的ls -
stat:文件信息 -
time:执行命令,并计算执行时间 -
timeout:在指定时长范围内执行命令,并在规定时间结束后停止进程 -
lockfile:使文件只能通过rm -f移除 -
logrotate: 切换、压缩以及发送日志文件 -
watch:重复运行同一个命令,展示结果并/或高亮有更改的部分 -
when-changed:当检测到文件更改时执行指定命令。参阅inotifywait和entr。 -
tac:反向输出文件 -
shuf:文件中随机选取几行 -
comm:一行一行的比较排序过的文件 -
strings:从二进制文件中抽取文本 -
tr:转换字母 -
iconv或uconv:文本编码转换 -
split和csplit:分割文件 -
sponge:在写入前读取所有输入,在读取文件后再向同一文件写入时比较有用,例如grep -v something some-file | sponge some-file -
units:将一种计量单位转换为另一种等效的计量单位(参阅/usr/share/units/definitions.units) -
apg:随机生成密码 -
xz:高比例的文件压缩 -
ldd:动态库信息 -
nm:提取 obj 文件中的符号 -
ab或wrk:web 服务器性能分析 -
strace:调试系统调用 -
mtr:更好的网络调试跟踪工具 -
cssh:可视化的并发 shell -
rsync:通过 ssh 或本地文件系统同步文件和文件夹 -
ngrep:网络层的 grep -
host和dig:DNS 查找 -
lsof:列出当前系统打开文件的工具以及查看端口信息 -
dstat:系统状态查看 -
glances:高层次的多子系统总览 -
iostat:硬盘使用状态 -
mpstat: CPU 使用状态 -
vmstat: 内存使用状态 -
htop:top 的加强版 -
last:登入记录 -
w:查看处于登录状态的用户 -
id:用户/组 ID 信息 -
sar:系统历史数据 -
ss:套接字数据 -
dmesg:引导及系统错误信息 -
sysctl: 在内核运行时动态地查看和修改内核的运行参数 -
hdparm:SATA/ATA 磁盘更改及性能分析 -
lsblk:列出块设备信息:以树形展示你的磁盘以及磁盘分区信息 -
lshw,lscpu,lspci,lsusb和dmidecode:查看硬件信息,包括 CPU、BIOS、RAID、显卡、USB设备等 -
lsmod和modinfo:列出内核模块,并显示其细节 -
fortune,ddate和sl:额,这主要取决于你是否认为蒸汽火车和莫名其妙的名人名言是否“有用”
仅限 OS X 系统
以下是仅限于 OS X 系统的技巧。
-
用
brew(Homebrew)或者port(MacPorts)进行包管理。这些可以用来在 OS X 系统上安装以上的大多数命令。 -
用
pbcopy复制任何命令的输出到桌面应用,用pbpaste粘贴输入。 -
若要在 OS X 终端中将 Option 键视为 alt 键(例如在上面介绍的 alt-b、alt-f 等命令中用到),打开 偏好设置 -> 描述文件 -> 键盘 并勾选“使用 Option 键作为 Meta 键”。
-
用
open或者open -a /Applications/Whatever.app使用桌面应用打开文件。 -
Spotlight:用
mdfind搜索文件,用mdls列出元数据(例如照片的 EXIF 信息)。 -
注意 OS X 系统是基于 BSD UNIX 的,许多命令(例如
ps,ls,tail,awk,sed)都和 Linux 中有微妙的不同( Linux 很大程度上受到了 System V-style Unix 和 GNU 工具影响)。你可以通过标题为 "BSD General Commands Manual" 的 man 页面发现这些不同。在有些情况下 GNU 版本的命令也可能被安装(例如gawk和gsed对应 GNU 中的 awk 和 sed )。如果要写跨平台的 Bash 脚本,避免使用这些命令(例如,考虑 Python 或者perl)或者经过仔细的测试。 -
用
sw_vers获取 OS X 的版本信息。
仅限 Windows 系统
以下是仅限于 Windows 系统的技巧。
在 Winodws 下获取 Unix 工具
-
可以安装 Cygwin 允许你在 Microsoft Windows 中体验 Unix shell 的威力。这样的话,本文中介绍的大多数内容都将适用。
-
在 Windows 10 上,你可以使用 Bash on Ubuntu on Windows,它提供了一个熟悉的 Bash 环境,包含了不少 Unix 命令行工具。好处是它允许 Linux 上编写的程序在 Windows 上运行,而另一方面,Windows 上编写的程序却无法在 Bash 命令行中运行。
-
如果你在 Windows 上主要想用 GNU 开发者工具(例如 GCC),可以考虑 MinGW 以及它的 MSYS 包,这个包提供了例如 bash,gawk,make 和 grep 的工具。MSYS 并不包含所有可以与 Cygwin 媲美的特性。当制作 Unix 工具的原生 Windows 端口时 MinGW 将特别地有用。
-
另一个在 Windows 下实现接近 Unix 环境外观效果的选项是 Cash。注意在此环境下只有很少的 Unix 命令和命令行可用。
实用 Windows 命令行工具
-
可以使用
wmic在命令行环境下给大部分 Windows 系统管理任务编写脚本以及执行这些任务。 -
Windows 实用的原生命令行网络工具包括
ping,ipconfig,tracert,和netstat。 -
可以使用
Rundll32命令来实现许多有用的 Windows 任务 。
Cygwin 技巧
-
通过 Cygwin 的包管理器来安装额外的 Unix 程序。
-
使用
mintty作为你的命令行窗口。 -
要访问 Windows 剪贴板,可以通过
/dev/clipboard。 -
运行
cygstart以通过默认程序打开一个文件。 -
要访问 Windows 注册表,可以使用
regtool。 -
注意 Windows 驱动器路径
C:\在 Cygwin 中用/cygdrive/c代表,而 Cygwin 的/代表 Windows 中的C:\cygwin。要转换 Cygwin 和 Windows 风格的路径可以用cygpath。这在需要调用 Windows 程序的脚本里很有用。 -
学会使用
wmic,你就可以从命令行执行大多数 Windows 系统管理任务,并编成脚本。 -
要在 Windows 下获得 Unix 的界面和体验,另一个办法是使用 Cash。需要注意的是,这个环境支持的 Unix 命令和命令行参数非常少。
-
要在 Windows 上获取 GNU 开发者工具(比如 GCC)的另一个办法是使用 MinGW 以及它的 MSYS 软件包,该软件包提供了 bash、gawk、make、grep 等工具。然而 MSYS 提供的功能没有 Cygwin 完善。MinGW 在创建 Unix 工具的 Windows 原生移植方面非常有用。
更多资源
- awesome-shell:一份精心组织的命令行工具及资源的列表。
- awesome-osx-command-line:一份针对 OS X 命令行的更深入的指南。
- Strict mode:为了编写更好的脚本文件。
- shellcheck:一个静态 shell 脚本分析工具,本质上是 bash/sh/zsh 的 lint。
- Filenames and Pathnames in Shell:有关如何在 shell 脚本里正确处理文件名的细枝末节。
- Data Science at the Command Line:用于数据科学的一些命令和工具,摘自同名书籍。
文件管理
cat
cat(英文全拼:concatenate)命令用于连接文件并打印到标准输出设备上。
概要
cat [-AbeEnstTuv] [--help] [--version] fileName
主要用途
-
显示文件内容,如果没有文件或文件为-则读取标准输入。
- 将多个文件的内容进行连接并打印到标准输出。
- 显示文件内容中的不可见字符(控制字符、换行符、制表符等)。
参数说明:
-n 或 --number:由 1 开始对所有输出的行数编号。
-b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号。
-s 或 --squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。
-v 或 --show-nonprinting:使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。
-E 或 --show-ends : 在每行结束处显示 $。
-T 或 --show-tabs: 将 TAB 字符显示为 ^I。
-A, --show-all:等价于 -vET。
-e:等价于"-vE"选项;
-t:等价于"-vT"选项;
返回值
返回状态为成功除非给出了非法选项或非法参数。
find命令
语法
find(选项)(参数)
Usage: find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path...] [expression]
default path is the current directory; default expression is -print
expression may consist of: operators, options, tests, and actions:
operators (decreasing precedence; -and is implicit where no others are given):
( EXPR ) ! EXPR -not EXPR EXPR1 -a EXPR2 EXPR1 -and EXPR2
EXPR1 -o EXPR2 EXPR1 -or EXPR2 EXPR1 , EXPR2
positional options (always true): -daystart -follow -regextype
normal options (always true, specified before other expressions):
-depth --help -maxdepth LEVELS -mindepth LEVELS -mount -noleaf
--version -xautofs -xdev -ignore_readdir_race -noignore_readdir_race
tests (N can be +N or -N or N): -amin N -anewer FILE -atime N -cmin N
-cnewer FILE -ctime N -empty -false -fstype TYPE -gid N -group NAME
-ilname PATTERN -iname PATTERN -inum N -iwholename PATTERN -iregex PATTERN
-links N -lname PATTERN -mmin N -mtime N -name PATTERN -newer FILE
-nouser -nogroup -path PATTERN -perm [-/]MODE -regex PATTERN
-readable -writable -executable
-wholename PATTERN -size N[bcwkMG] -true -type [bcdpflsD] -uid N
-used N -user NAME -xtype [bcdpfls]
-context CONTEXT
actions: -delete -print0 -printf FORMAT -fprintf FILE FORMAT -print
-fprint0 FILE -fprint FILE -ls -fls FILE -prune -quit
-exec COMMAND ; -exec COMMAND {} + -ok COMMAND ;
-execdir COMMAND ; -execdir COMMAND {} + -okdir COMMAND ;
主要用途
-
用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
-
在指定目录下查找文件
参数说明:
find 根据下列规则判断 path 和 expression,在命令列上第一个 - ( ) , ! 之前的部份为 path,之后的是 expression。如果 path 是空字串则使用目前路径,如果 expression 是空字串则使用 -print 为预设 expression。
expression 中可使用的选项有二三十个之多,在此只介绍最常用的部份。
-mount, -xdev : 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件
-amin n : 在过去 n 分钟内被读取过
-anewer file : 比文件 file 更晚被读取过的文件
-atime n : 在过去n天内被读取过的文件
-cmin n : 在过去 n 分钟内被修改过
-cnewer file :比文件 file 更新的文件
-ctime n : 在过去n天内被修改过的文件
-empty : 空的文件-gid n or -group name : gid 是 n 或是 group 名称是 name
-ipath p, -path p : 路径名称符合 p 的文件,ipath 会忽略大小写
-name name, -iname name : 文件名称符合 name 的文件。iname 会忽略大小写
-size n : 文件大小 是 n 单位,b 代表 512 位元组的区块,c 表示字元数,k 表示 kilo bytes,w 是二个位元组。
-type c : 文件类型是 c 的文件。
d: 目录
c: 字型装置文件
b: 区块装置文件
p: 具名贮列
f: 一般文件
l: 符号连结
s: socket
-pid n : process id 是 n 的文件
你可以使用 ( ) 将运算式分隔,并使用下列运算。
exp1 -and exp2
! expr
-not expr
exp1 -or exp2
exp1, exp2
实例
- 查找当前目录的下的已txt 结尾的文件 find -name "*.txt"
- 列出当前目录下的目录 find . -type d
- 找出当前目录下的txt的文件并使用cat命令输出到阿all.txt文件中 find . -type f -name "*.txt" -exec cat {} \;> /all.txt
- 查看当前目录下3天内读取的文件 find . -atime -3
- 查找当前目录大于100k的文件 find . -type f -size +100k
- 打印当前目录下不是目录的以文件名localhost开头的文件 find . -name "localhost*" ! -type d -print
more命令
语法
more [-dlfpcsu] [-num] [+/pattern] [+linenum] [fileNames..]
主要用途
-
Linux more 命令类似 cat ,不过会以一页一页的形式显示,更方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示,而且还有搜寻字串的功能(与 vi 相似),使用中的说明文件,请按 h 。
参数说明:
- -num 一次显示的行数
- -d 提示使用者,在画面下方显示 [Press space to continue, 'q' to quit.] ,如果使用者按错键,则会显示 [Press 'h' for instructions.] 而不是 '哔' 声
- -l 取消遇见特殊字元 ^L(送纸字元)时会暂停的功能
- -f 计算行数时,以实际上的行数,而非自动换行过后的行数(有些单行字数太长的会被扩展为两行或两行以上)
- -p 不以卷动的方式显示每一页,而是先清除萤幕后再显示内容
- -c 跟 -p 相似,不同的是先显示内容再清除其他旧资料
- -s 当遇到有连续两行以上的空白行,就代换为一行的空白行
- -u 不显示下引号 (根据环境变数 TERM 指定的 terminal 而有所不同)
- +/pattern 在每个文档显示前搜寻该字串(pattern),然后从该字串之后开始显示
- +num 从第 num 行开始显示
- fileNames 欲显示内容的文档,可为复数个数
实例
- 每页显示日志的30行 more -d -30 catalina.out
less命令
语法
less [参数] 文件
more [options] file...
主要用途
-
less 与 more 类似,less 可以随意浏览文件,支持翻页和搜索,支持向上翻页和向下翻页。
-
导出文件内容
参数说明:
SUMMARY OF LESS COMMANDS
Commands marked with * may be preceded by a number, N.
Notes in parentheses indicate the behavior if N is given.
A key preceded by a caret indicates the Ctrl key; thus ^K is ctrl-K.
h H Display this help.
q :q Q :Q ZZ Exit.
---------------------------------------------------------------------------
MOVING
e ^E j ^N CR * Forward one line (or N lines).
y ^Y k ^K ^P * Backward one line (or N lines).
f ^F ^V SPACE * Forward one window (or N lines).
b ^B ESC-v * Backward one window (or N lines).
z * Forward one window (and set window to N).
w * Backward one window (and set window to N).
ESC-SPACE * Forward one window, but don't stop at end-of-file.
d ^D * Forward one half-window (and set half-window to N).
u ^U * Backward one half-window (and set half-window to N).
ESC-) RightArrow * Left one half screen width (or N positions).
ESC-( LeftArrow * Right one half screen width (or N positions).
F Forward forever; like "tail -f".
r ^R ^L Repaint screen.
R Repaint screen, discarding buffered input.
---------------------------------------------------
Default "window" is the screen height.
Default "half-window" is half of the screen height.
---------------------------------------------------------------------------
SEARCHING
/pattern * Search forward for (N-th) matching line.
?pattern * Search backward for (N-th) matching line.
n * Repeat previous search (for N-th occurrence).
N * Repeat previous search in reverse direction.
ESC-n * Repeat previous search, spanning files.
ESC-N * Repeat previous search, reverse dir. & spanning files.
ESC-u Undo (toggle) search highlighting.
&pattern * Display only matching lines
---------------------------------------------------
A search pattern may be preceded by one or more of:
^N or ! Search for NON-matching lines.
^E or * Search multiple files (pass thru END OF FILE).
^F or @ Start search at FIRST file (for /) or last file (for ?).
^K Highlight matches, but don't move (KEEP position).
^R Don't use REGULAR EXPRESSIONS.
---------------------------------------------------------------------------
JUMPING
g < ESC-< * Go to first line in file (or line N).
G > ESC-> * Go to last line in file (or line N).
p % * Go to beginning of file (or N percent into file).
t * Go to the (N-th) next tag.
T * Go to the (N-th) previous tag.
{ ( [ * Find close bracket } ) ].
} ) ] * Find open bracket { ( [.
ESC-^F <c1> <c2> * Find close bracket <c2>.
ESC-^B <c1> <c2> * Find open bracket <c1>
---------------------------------------------------
Each "find close bracket" command goes forward to the close bracket
matching the (N-th) open bracket in the top line.
Each "find open bracket" command goes backward to the open bracket
matching the (N-th) close bracket in the bottom line.
m<letter> Mark the current position with <letter>.
'<letter> Go to a previously marked position.
'' Go to the previous position.
^X^X Same as '.
---------------------------------------------------
A mark is any upper-case or lower-case letter.
Certain marks are predefined:
^ means beginning of the file
$ means end of the file
---------------------------------------------------------------------------
CHANGING FILES
:e [file] Examine a new file.
^X^V Same as :e.
:n * Examine the (N-th) next file from the command line.
:p * Examine the (N-th) previous file from the command line.
:x * Examine the first (or N-th) file from the command line.
:d Delete the current file from the command line list.
= ^G :f Print current file name.
---------------------------------------------------------------------------
MISCELLANEOUS COMMANDS
-<flag> Toggle a command line option [see OPTIONS below].
--<name> Toggle a command line option, by name.
_<flag> Display the setting of a command line option.
__<name> Display the setting of an option, by name.
+cmd Execute the less cmd each time a new file is examined.
!command Execute the shell command with $SHELL.
|Xcommand Pipe file between current pos & mark X to shell command.
v Edit the current file with $VISUAL or $EDITOR.
V Print version number of "less".
---------------------------------------------------------------------------
OPTIONS
Most options may be changed either on the command line,
or from within less by using the - or -- command.
Options may be given in one of two forms: either a single
character preceded by a -, or a name preceded by --.
-? ........ --help
Display help (from command line).
-a ........ --search-skip-screen
Search skips current screen.
-A ........ --SEARCH-SKIP-SCREEN
Search starts just after target line.
-b [N] .... --buffers=[N]
Number of buffers.
-B ........ --auto-buffers
Don't automatically allocate buffers for pipes.
-c -C .... --clear-screen --CLEAR-SCREEN
Repaint by clearing rather than scrolling.
-d ........ --dumb
Dumb terminal.
-D [xn.n] . --color=xn.n
Set screen colors. (MS-DOS only)
-e -E .... --quit-at-eof --QUIT-AT-EOF
Quit at end of file.
-f ........ --force
Force open non-regular files.
-F ........ --quit-if-one-screen
Quit if entire file fits on first screen.
-g ........ --hilite-search
Highlight only last match for searches.
-G ........ --HILITE-SEARCH
Don't highlight any matches for searches.
--old-bot
Revert to the old bottom of screen behavior.
-h [N] .... --max-back-scroll=[N]
Backward scroll limit.
-i ........ --ignore-case
Ignore case in searches that do not contain uppercase.
-I ........ --IGNORE-CASE
Ignore case in all searches.
-j [N] .... --jump-target=[N]
Screen position of target lines.
-J ........ --status-column
Display a status column at left edge of screen.
-k [file] . --lesskey-file=[file]
Use a lesskey file.
-K --quit-on-intr
Exit less in response to ctrl-C.
-L ........ --no-lessopen
Ignore the LESSOPEN environment variable.
-m -M .... --long-prompt --LONG-PROMPT
Set prompt style.
-n ........ --line-numbers
Don't use line numbers.
-N ........ --LINE-NUMBERS
Use line numbers.
-o [file] . --log-file=[file]
Copy to log file (standard input only).
-O [file] . --LOG-FILE=[file]
Copy to log file (unconditionally overwrite).
-p [pattern] --pattern=[pattern]
Start at pattern (from command line).
-P [prompt] --prompt=[prompt]
Define new prompt.
-q -Q .... --quiet --QUIET --silent --SILENT
Quiet the terminal bell.
-r -R .... --raw-control-chars --RAW-CONTROL-CHARS
Output "raw" control characters.
-s ........ --squeeze-blank-lines
Squeeze multiple blank lines.
-S ........ --chop-long-lines
Chop (truncate) long lines rather than wrapping.
-t [tag] .. --tag=[tag]
Find a tag.
-T [tagsfile] --tag-file=[tagsfile]
Use an alternate tags file.
-u -U .... --underline-special --UNDERLINE-SPECIAL
Change handling of backspaces.
-V ........ --version
Display the version number of "less".
-w ........ --hilite-unread
Highlight first new line after forward-screen.
-W ........ --HILITE-UNREAD
Highlight first new line after any forward movement.
-x [N[,...]] --tabs=[N[,...]]
Set tab stops.
-X ........ --no-init
Don't use termcap init/deinit strings.
-y [N] .... --max-forw-scroll=[N]
Forward scroll limit.
-z [N] .... --window=[N]
Set size of window.
-" [c[c]] . --quotes=[c[c]]
Set shell quote characters.
-~ ........ --tilde
Don't display tildes after end of file.
-# [N] .... --shift=[N]
Horizontal scroll amount (0 = one half screen width)
........ --no-keypad
Don't send termcap keypad init/deinit strings.
........ --follow-name
The F command changes files if the input file is renamed.
........ --use-backslash
Subsequent options use backslash as escape char.
---------------------------------------------------------------------------
LINE EDITING
These keys can be used to edit text being entered
on the "command line" at the bottom of the screen.
RightArrow ESC-l Move cursor right one character.
LeftArrow ESC-h Move cursor left one character.
ctrl-RightArrow ESC-RightArrow ESC-w Move cursor right one word.
ctrl-LeftArrow ESC-LeftArrow ESC-b Move cursor left one word.
HOME ESC-0 Move cursor to start of line.
END ESC-$ Move cursor to end of line.
BACKSPACE Delete char to left of cursor.
DELETE ESC-x Delete char under cursor.
ctrl-BACKSPACE ESC-BACKSPACE Delete word to left of cursor.
ctrl-DELETE ESC-DELETE ESC-X Delete word under cursor.
ctrl-U ESC (MS-DOS only) Delete entire line.
UpArrow ESC-k Retrieve previous command line.
DownArrow ESC-j Retrieve next command line.
TAB Complete filename & cycle.
SHIFT-TAB ESC-TAB Complete filename & reverse cycle.
ctrl-L Complete filename, list all.
实例
- 显示文件类容并将连续空行压缩成一行显示 less -s file.log
- less test.txt 按/键搜索 然后按n向后搜索,N向前搜索, 按Shift + G 从文件的末尾浏览
- less -N +10 test.txt 跳转到第10行
- less filename.txt > output.txt 文件内容到处到其他文件
cp 命令
用于复制文件或目录。
语法
cp [OPTION]... [-T] SOURCE DEST
or: cp [OPTION]... SOURCE... DIRECTORY
or: cp [OPTION]... -t DIRECTORY SOURCE...
主要用途
-
用于复制文件或目录。
参数说明:
- -a:此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。
- -d:复制时保留链接。这里所说的链接相当于 Windows 系统中的快捷方式。
- -f:覆盖已经存在的目标文件而不给出提示。
- -i:与 -f 选项相反,在覆盖目标文件之前给出提示,要求用户确认是否覆盖,回答 y 时目标文件将被覆盖。
- -p:除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。
- -r:若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。
- -l:不复制文件,只是生成链接文件。
-a, --archive same as -dR --preserve=all
--attributes-only don't copy the file data, just the attributes
--backup[=CONTROL] make a backup of each existing destination file
-b like --backup but does not accept an argument
--copy-contents copy contents of special files when recursive
-d same as --no-dereference --preserve=links
-f, --force if an existing destination file cannot be
opened, remove it and try again (this option
is ignored when the -n option is also used)
-i, --interactive prompt before overwrite (overrides a previous -n
option)
-H follow command-line symbolic links in SOURCE
-l, --link hard link files instead of copying
-L, --dereference always follow symbolic links in SOURCE
-n, --no-clobber do not overwrite an existing file (overrides
a previous -i option)
-P, --no-dereference never follow symbolic links in SOURCE
-p same as --preserve=mode,ownership,timestamps
--preserve[=ATTR_LIST] preserve the specified attributes (default:
mode,ownership,timestamps), if possible
additional attributes: context, links, xattr,
all
-c deprecated, same as --preserve=context
--no-preserve=ATTR_LIST don't preserve the specified attributes
--parents use full source file name under DIRECTORY
-R, -r, --recursive copy directories recursively
--reflink[=WHEN] control clone/CoW copies. See below
--remove-destination remove each existing destination file before
attempting to open it (contrast with --force)
--sparse=WHEN control creation of sparse files. See below
--strip-trailing-slashes remove any trailing slashes from each SOURCE
argument
-s, --symbolic-link make symbolic links instead of copying
-S, --suffix=SUFFIX override the usual backup suffix
-t, --target-directory=DIRECTORY copy all SOURCE arguments into DIRECTORY
-T, --no-target-directory treat DEST as a normal file
-u, --update copy only when the SOURCE file is newer
than the destination file or when the
destination file is missing
-v, --verbose explain what is being done
-x, --one-file-system stay on this file system
-Z set SELinux security context of destination
file to default type
--context[=CTX] like -Z, or if CTX is specified then set the
SELinux or SMACK security context to CTX
--help display this help and exit
--version output version information and exit
实例
-
cp –r test/ newtest 将test目录下的所有文件复制到 newtest
-
cp -i test.txt test1.txt 如果已经有tes1.txt文件,提示是否覆盖
-
cp -p test.txt origin.txt 复制文件保留文件元数据信息(权限,时间戳)
touch命令
touch 命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
语法
touch [OPTION]... FILE...
主要用途
-
创建空白文件: 最常见的用途是创建新的空白文件。如果指定的文件不存在,
touch命令将会创建一个名为指定文件名的空白文件。这对于快速创建占位符文件、空白配置文件或测试文件非常有用。 -
更新文件时间戳:
touch命令还可以用于更新文件的访问时间(atime)和修改时间(mtime)戳。通过执行touch命令,你可以将一个现有文件的时间戳更新为当前时间,而不实际更改文件内容。这在一些特定情况下很有用,例如在需要监视文件的访问时间时。 -
批量创建多个文件:
touch命令可以一次创建多个文件,只需在命令后列出多个文件名即可。这对于需要批量创建多个文件的情况非常方便。 -
创建文件并指定时间戳: 使用
touch命令,你可以创建一个文件并同时指定它的访问时间和修改时间。这可以通过-t选项来完成。
参数说明:
- a:或--time=atime或--time=access或--time=use 只更改存取时间;
- -c:或--no-create 不建立任何文件;
- -d:<时间日期> 使用指定的日期时间,而非现在的时间;
- -f:此参数将忽略不予处理,仅负责解决BSD版本touch指令的兼容性问题;
- -m:或--time=mtime或--time=modify 只更该变动时间;
- -r:<参考文件或目录> 把指定文件或目录的日期时间,统统设成和参考文件或目录的日期时间相同;
- -t:<日期时间> 使用指定的日期时间,而非现在的时间;
- --help:在线帮助;
- --version:显示版本信息。
-a change only the access time
-c, --no-create do not create any files
-d, --date=STRING parse STRING and use it instead of current time
-f (ignored)
-h, --no-dereference affect each symbolic link instead of any referenced file (useful only on systems that can change the timestamps of a symlink)
-m change only the modification time
-r, --reference=FILE use this file's times instead of current time
-t STAMP use [[CC]YY]MMDDhhmm[.ss] instead of current time
--time=WORD change the specified time:
WORD is access, atime, or use: equivalent to -a
WORD is modify or mtime: equivalent to -m
--help display this help and exit
--version output version information and exit
Note that the -d and -t options accept different time-date formats.
实例
touch filename.txt 创建一个txt文件
touch -c filename.txt 更新文件的修改时间为当前时间
touch file1.txt file2.txt file3.txt 一次性创建多个文件
touch -t 202310260930.00 filename.txt 设置或修改文件时间戳
chmod命令
语法
chmod [OPTION]... MODE[,MODE]... FILE...
chmod [OPTION]... OCTAL-MODE FILE...
chmod [OPTION]... --reference=RFILE FILE...
主要用途
-
更改文件或目录的权限:添加或删除文件的读、写、执行权限,以控制谁可以对文件进行何种操作。
-
以符号模式或数字模式设置权限:符号模式(如
u+rwx):使用符号来表示权限更改,u表示所有者,g表示所属组,o表示其他用户,+表示添加权限,-表示删除权限,=表示设置权限。数字模式(如chmod 755 file.txt):使用数字来表示权限,数字的组合代表了不同的权限组合,比如 7 表示读、写、执行权限,5 表示读和执行权限,0 表示没有权限。 -
递归修改目录及其子目录的权限:使用
-R选项可以递归地更改目录及其内部文件的权限。 -
管理文件安全性和访问控制:
chmod可以帮助系统管理员限制或授权用户对文件和目录的访问权限,提高文件和系统的安全性。 -
管理可执行文件:对于可执行文件,
chmod可以控制谁可以运行它,对于脚本文件也可以设置是否可执行。
参数说明:
With --reference, change the mode of each FILE to that of RFILE.
-c, --changes like verbose but report only when a change is made
-f, --silent, --quiet suppress most error messages
-v, --verbose output a diagnostic for every file processed
--no-preserve-root do not treat '/' specially (the default)
--preserve-root fail to operate recursively on '/'
--reference=RFILE use RFILE's mode instead of MODE values
-R, --recursive change files and directories recursively
--help display this help and exit
--version output version information and exit
Each MODE is of the form '[ugoa]*([-+=]([rwxXst]*|[ugo]))+|[-+=][0-7]+'.
-c, --changes: 仅在更改了文件的权限时显示消息。-f, --silent, --quiet: 不显示错误消息。-v, --verbose: 显示详细的输出,显示每个文件的权限更改信息。-R, --recursive: 递归地更改目录及其内部文件的权限。u表示文件所有者(user),g表示用户组(group),o表示其他用户(others),+表示添加权限,-表示去除权限,r表示读权限,w表示写权限,x表示执行权限。4表示只读权限 (r),2表示写入权限 (w),1表示执行或访问权限 (x)
实例
- chmod +x file.txt # 给文件添加执行权限
- chmod g+w,o+w file.txt # 给文件的所属组和其他用户添加写权限
- chmod -r file.txt # 删除文件的读权限
- chmod go-rwx file.txt # 删除文件的所属组和其他用户的所有权限
- chmod 755 file.txt # 设置文件所有者具有读、写、执行权限,所属组和其他用户具有读、执行权限
- chmod 644 file.txt # 设置文件所有者具有读、写权限,所属组和其他用户具有只读权限
- chmod -R 755 directory # 递归地将目录及其内部所有文件和子目录设置为指定权限
- chmod -v +x file.txt # 显示对文件添加执行权限的详细信息

- chmod -c -R 600 directory # 仅显示更改了权限的文件信息(递归修改目录权限)
文档编辑
grep命令
global search regular expression(RE) and print out the line
语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
grep [OPTION]... PATTERN [FILE]...
主要用途
-
Linux grep 命令用于查找文件里符合条件的字符串。
-
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
参数说明:
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 --only-matching : 只显示匹配PATTERN 部分。
- -q 或 --quiet或--silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --invert-match : 显示不包含匹配文本的所有行。
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
Regexp selection and interpretation:
-E, --extended-regexp PATTERN is an extended regular expression (ERE)
-F, --fixed-strings PATTERN is a set of newline-separated fixed strings
-G, --basic-regexp PATTERN is a basic regular expression (BRE)
-P, --perl-regexp PATTERN is a Perl regular expression
-e, --regexp=PATTERN use PATTERN for matching
-f, --file=FILE obtain PATTERN from FILE
-i, --ignore-case ignore case distinctions
-w, --word-regexp force PATTERN to match only whole words
-x, --line-regexp force PATTERN to match only whole lines
-z, --null-data a data line ends in 0 byte, not newline
Miscellaneous:
-s, --no-messages suppress error messages
-v, --invert-match select non-matching lines
-V, --version display version information and exit
--help display this help text and exit
Output control:
-m, --max-count=NUM stop after NUM matches
-b, --byte-offset print the byte offset with output lines
-n, --line-number print line number with output lines
--line-buffered flush output on every line
-H, --with-filename print the file name for each match
-h, --no-filename suppress the file name prefix on output
--label=LABEL use LABEL as the standard input file name prefix
-o, --only-matching show only the part of a line matching PATTERN
-q, --quiet, --silent suppress all normal output
--binary-files=TYPE assume that binary files are TYPE;
TYPE is 'binary', 'text', or 'without-match'
-a, --text equivalent to --binary-files=text
-I equivalent to --binary-files=without-match
-d, --directories=ACTION how to handle directories;
ACTION is 'read', 'recurse', or 'skip'
-D, --devices=ACTION how to handle devices, FIFOs and sockets;
ACTION is 'read' or 'skip'
-r, --recursive like --directories=recurse
-R, --dereference-recursive
likewise, but follow all symlinks
--include=FILE_PATTERN
search only files that match FILE_PATTERN
--exclude=FILE_PATTERN
skip files and directories matching FILE_PATTERN
--exclude-from=FILE skip files matching any file pattern from FILE
--exclude-dir=PATTERN directories that match PATTERN will be skipped.
-L, --files-without-match print only names of FILEs containing no match
-l, --files-with-matches print only names of FILEs containing matches
-c, --count print only a count of matching lines per FILE
-T, --initial-tab make tabs line up (if needed)
-Z, --null print 0 byte after FILE name
Context control:
-B, --before-context=NUM print NUM lines of leading context
-A, --after-context=NUM print NUM lines of trailing context
-C, --context=NUM print NUM lines of output context
-NUM same as --context=NUM
--group-separator=SEP use SEP as a group separator
--no-group-separator use empty string as a group separator
--color[=WHEN],
--colour[=WHEN] use markers to highlight the matching strings;
WHEN is 'always', 'never', or 'auto'
-U, --binary do not strip CR characters at EOL (MSDOS/Windows)
-u, --unix-byte-offsets report offsets as if CRs were not there
(MSDOS/Windows)
'egrep' means 'grep -E'. 'fgrep' means 'grep -F'.
Direct invocation as either 'egrep' or 'fgrep' is deprecated.
When FILE is -, read standard input. With no FILE, read . if a command-line
-r is given, - otherwise. If fewer than two FILEs are given, assume -h.
Exit status is 0 if any line is selected, 1 otherwise;
if any error occurs and -q is not given, the exit status is 2.
实例
- 显示test.txt 中包含log的行及其之后的两行 grep -A2 log test.txt
- 查找/test/目录下包含"consul"的文件并打印行号 grep -r consul /test/
- 查找test.txt中包含至少1位的数字 grep -P "\d+" test.txt
sort命令
语法
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件][-k field1[,field2]]
sort [OPTION]... [FILE]...
or: sort [OPTION]... --files0-from=F
主要用途
-
Linux sort 命令用于将文本文件内容加以排序。
-
sort 可针对文本文件的内容,以行为单位来排序。
参数说明:
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- --help 显示帮助。
- --version 显示版本信息。
- [-k field1[,field2]] 按指定的列进行排序。
-b, --ignore-leading-blanks ignore leading blanks
-d, --dictionary-order consider only blanks and alphanumeric characters
-f, --ignore-case fold lower case to upper case characters
-g, --general-numeric-sort compare according to general numerical value
-i, --ignore-nonprinting consider only printable characters
-M, --month-sort compare (unknown) < 'JAN' < ... < 'DEC'
-h, --human-numeric-sort compare human readable numbers (e.g., 2K 1G)
-n, --numeric-sort compare according to string numerical value
-R, --random-sort sort by random hash of keys
--random-source=FILE get random bytes from FILE
-r, --reverse reverse the result of comparisons
--sort=WORD sort according to WORD:
general-numeric -g, human-numeric -h, month -M,
numeric -n, random -R, version -V
-V, --version-sort natural sort of (version) numbers within text
Other options:
--batch-size=NMERGE merge at most NMERGE inputs at once;
for more use temp files
-c, --check, --check=diagnose-first check for sorted input; do not sort
-C, --check=quiet, --check=silent like -c, but do not report first bad line
--compress-program=PROG compress temporaries with PROG;
decompress them with PROG -d
--debug annotate the part of the line used to sort,
and warn about questionable usage to stderr
--files0-from=F read input from the files specified by
NUL-terminated names in file F;
If F is - then read names from standard input
-k, --key=KEYDEF sort via a key; KEYDEF gives location and type
-m, --merge merge already sorted files; do not sort
-o, --output=FILE write result to FILE instead of standard output
-s, --stable stabilize sort by disabling last-resort comparison
-S, --buffer-size=SIZE use SIZE for main memory buffer
-t, --field-separator=SEP use SEP instead of non-blank to blank transition
-T, --temporary-directory=DIR use DIR for temporaries, not $TMPDIR or /tmp;
multiple options specify multiple directories
--parallel=N change the number of sorts run concurrently to N
-u, --unique with -c, check for strict ordering;
without -c, output only the first of an equal run
-z, --zero-terminated end lines with 0 byte, not newline
--help display this help and exit
--version output version information and exit
--batch-size=NMERGE 一次合并最多NMERGE个输入;超过部分使用临时文件。
-c, --check, --check=diagnose-first 检查输入是否已排序,该操作不会执行排序。
-C, --check=quiet, --check=silent 类似于 -c 选项,但不输出第一个未排序的行。
--compress-program=PROG 使用PROG压缩临时文件;使用PROG -d解压缩。
--debug 注释用于排序的行,发送可疑用法的警报到stderr。
--files0-from=F 从文件F中读取以NUL结尾的所有文件名称;如果F是 - ,那么从标准输入中读取名字。
-k, --key=KEYDEF 通过一个key排序;KEYDEF给出位置和类型。
-m, --merge 合并已排序文件,之后不再排序。
-o, --output=FILE 将结果写入FILE而不是标准输出。
-s, --stable 通过禁用最后的比较来稳定排序。
-S, --buffer-size=SIZE 使用SIZE作为内存缓存大小。
-t, --field-separator=SEP 使用SEP作为列的分隔符。
-T, --temporary-directory=DIR 使用DIR作为临时目录,而不是 $TMPDIR 或 /tmp;多次使用该选项指定多个临时目录。
--parallel=N 将并发运行的排序数更改为N。
-u, --unique 同时使用-c,严格检查排序;不同时使用-c,输出排序后去重的结果。
-z, --zero-terminated 设置行终止符为NUL(空),而不是换行符。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
KEYDEF的格式为:F[.C][OPTS][,F[.C][OPTS]] ,表示开始到结束的位置。
F表示列的编号
C表示
OPTS为[bdfgiMhnRrV]中的一到多个字符,用于覆盖当前排序选项。
使用--debug选项可诊断出错误的用法。
实例
排序文件 sort.txt
经典 903799 10
心理 388714 20
美术 4815 30
通信 4815 16
韩寒 263120 4
投资 222242 506
随笔 1109774 50
养生 36101 51
情感 80158 55
科普 565211 10
戏剧 105027 54
- 已制表符为分隔符对第二列已数值大小排序,在此基础上对第三列排序 sort -t $'\t' -n -k2 -k3 sort.txt
awk命令
AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法
awk [选项参数] 'script' var=value file(s)
awk [选项参数] -f scriptfile var=value file(s)
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
主要用途
-
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
参数说明:
- -F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 - -v var=value or --asign var=value
赋值一个用户定义变量。 - -f scripfile or --file scriptfile
从脚本文件中读取awk命令。 - -mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 - -W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 - -W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。 - -W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。 - -W lint or --lint
打印不能向传统unix平台移植的结构的警告。 - -W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。 - -W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。 - -W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 - -W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。 - -W version or --version
打印bug报告信息的版本。
POSIX options: GNU long options: (standard)
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
Short options: GNU long options: (extensions)
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[file] --dump-variables[=file]
-e 'program-text' --source='program-text'
-E file --exec=file
-g --gen-pot
-h --help
-L [fatal] --lint[=fatal]
-n --non-decimal-data
-N --use-lc-numeric
-O --optimize
-p[file] --profile[=file]
-P --posix
-r --re-interval
-S --sandbox
-t --lint-old
-V --version
实例
例子文件 covid.txt
吉布提,Djibouti,5841,2021-1-2
多米尼克,Dominica,88,2021-1-2
多米尼加,Dominican Republic,172965,2021-1-2
厄瓜多尔,Ecuador,214513,2021-1-2
埃及,Egypt,140878,2021-1-2
萨尔瓦多,El Salvador,46803,2021-1-2
赤道几内亚,Equatorial Guinea,5277,2021-1-2
厄立特里亚,Eritrea,1320,2021-1-2
爱沙尼亚,Estonia,28789,2021-1-2
斯威士兰,Eswatini,9711,2021-1-2
埃塞俄比亚,Ethiopia,125049,2021-1-2
斐济,Fiji,49,2021-1-2
芬兰,Finland,36604,2021-1-2
法国,France,2700480,2021-1-2
加蓬,Gabon,9571,2021-1-2
冈比亚,Gambia,3800,2021-1-2
格鲁吉亚,Georgia,228752,2021-1-2
德国,Germany,1773540,2021-1-2
印尼,Indonesia,751270,2021-1-1
伊朗,Iran,1231429,2021-1-1
伊拉克,Iraq,596193,2021-1-1
爱尔兰,Ireland,93532,2021-1-1
以色列,Israel,428510,2021-1-1
- 已逗号分隔打印第二列 awk -F , '{print $2}' covid.txt
- 按行打印每一列,NR已读取的行,NF最后一个字段 awk -F , '{print "Line No:"NR", No of fields:"NF, "$1="$1, "$2="$2, "$3="$3}' covid.txt
- 计算第三列的总和 awk -F , 'BEGIN{ sum=0; print "总和:" } { print $3"+"; sum+=$3 } END{ print "等于"; print sum }' covid.txt
vi命令
功能强大的纯文本编辑器
语法
vim [arguments] [file ..] edit specified file(s) vim [arguments] - read text from stdin vim [arguments] -t tag edit file where tag is defined
主要用途
-
vi命令 是UNIX操作系统和类UNIX操作系统中最通用的全屏幕纯文本编辑器。Linux中的vi编辑器叫vim,它是vi的增强版(vi Improved),与vi编辑器完全兼容,而且实现了很多增强功能。
-
vi编辑器支持编辑模式和命令模式,编辑模式下可以完成文本的编辑功能,命令模式下可以完成对文件的操作命令,要正确使用vi编辑器就必须熟练掌握着两种模式的切换。默认情况下,打开vi编辑器后自动进入命令模式。从编辑模式切换到命令模式使用“esc”键,从命令模式切换到编辑模式使用“A”、“a”、“O”、“o”、“I”、“i”键。
-
vi编辑器提供了丰富的内置命令,有些内置命令使用键盘组合键即可完成,有些内置命令则需要以冒号“:”开头输入。
参数说明:
-- Only file names after this
-v Vi mode (like "vi")
-e Ex mode (like "ex")
-E Improved Ex mode
-s Silent (batch) mode (only for "ex")
-y Easy mode (like "evim", modeless)
-R Readonly mode (like "view")
-Z Restricted mode (like "rvim")
-m Modifications (writing files) not allowed
-M Modifications in text not allowed
-b Binary mode
-C Compatible with Vi: 'compatible'
-N Not fully Vi compatible: 'nocompatible'
-V[N][fname] Be verbose [level N] [log messages to fname]
-n No swap file, use memory only
-r List swap files and exit
-r (with file name) Recover crashed session
-L Same as -r
-T <terminal> Set terminal type to <terminal>
-u <vimrc> Use <vimrc> instead of any .vimrc
--noplugin Don't load plugin scripts
-p[N] Open N tab pages (default: one for each file)
-o[N] Open N windows (default: one for each file)
-O[N] Like -o but split vertically
+ Start at end of file
+<lnum> Start at line <lnum>
--cmd <command> Execute <command> before loading any vimrc file
-c <command> Execute <command> after loading the first file
-S <session> Source file <session> after loading the first file
-s <scriptin> Read Normal mode commands from file <scriptin>
-w <scriptout> Append all typed commands to file <scriptout>
-W <scriptout> Write all typed commands to file <scriptout>
-h or --help Print Help (this message) and exit
--version Print version information and exit
+<行号>:从指定行号的行开始显示文本内容;
-b:以二进制模式打开文件,用于编辑二进制文件和可执行文件;
-c<指令>:在完成对第一个文件编辑任务后,执行给出的指令;
-d:以diff模式打开文件,当多个文件编辑时,显示文件差异部分;
-l:使用lisp模式,打开“lisp”和“showmatch”;
-m:取消写文件功能,重设“write”选项;
-M:关闭修改功能;
-n:不实用缓存功能;
-o<文件数目>:指定同时打开指定数目的文件;
-R:以只读方式打开文件;
-s:安静模式,不现实指令的任何错误信息。
实例
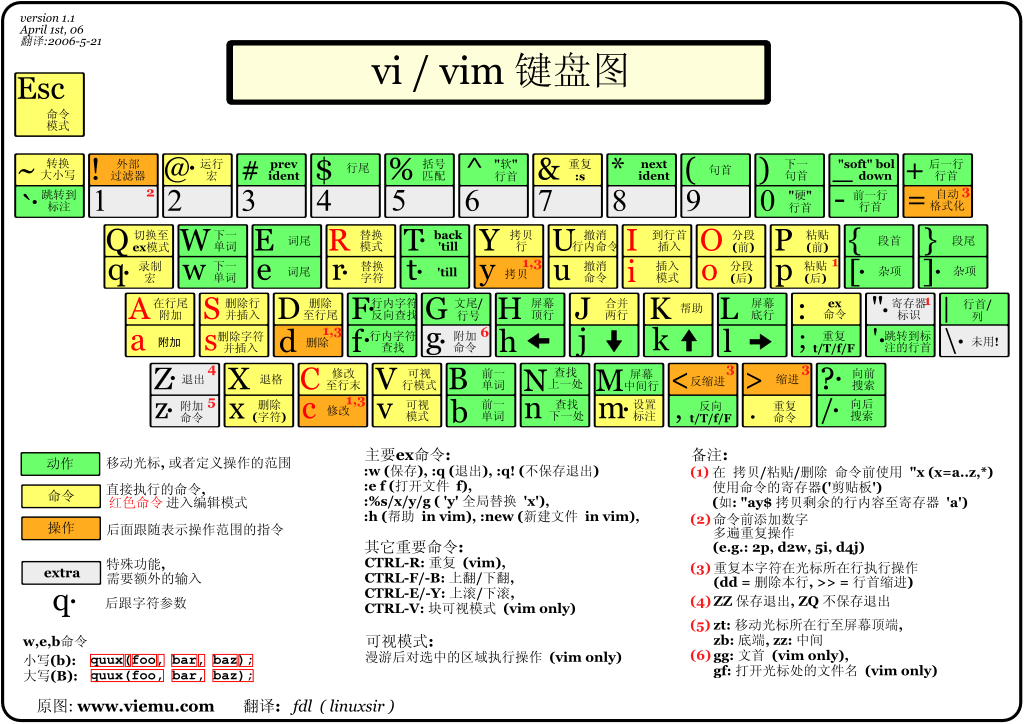
Ctrl+u:向文件首翻半屏;
Ctrl+d:向文件尾翻半屏;
Ctrl+f:向文件尾翻一屏;
Ctrl+b:向文件首翻一屏;
Esc:从编辑模式切换到命令模式;
ZZ:命令模式下保存当前文件所做的修改后退出vi;
:行号:光标跳转到指定行的行首;
:$:光标跳转到最后一行的行首;
x或X:删除一个字符,x删除光标后的,而X删除光标前的;
D:删除从当前光标到光标所在行尾的全部字符;
dd:删除光标行正行内容;
ndd:删除当前行及其后n-1行;
nyy:将当前行及其下n行的内容保存到寄存器?中,其中?为一个字母,n为一个数字;
p:粘贴文本操作,用于将缓存区的内容粘贴到当前光标所在位置的下方;
P:粘贴文本操作,用于将缓存区的内容粘贴到当前光标所在位置的上方;
/字符串:文本查找操作,用于从当前光标所在位置开始向文件尾部查找指定字符串的内容,查找的字符串会被加亮显示;
?字符串:文本查找操作,用于从当前光标所在位置开始向文件头部查找指定字符串的内容,查找的字符串会被加亮显示;
a,bs/F/T:替换文本操作,用于在第a行到第b行之间,将F字符串换成T字符串。其中,“s/”表示进行替换操作;
a:在当前字符后添加文本;
A:在行末添加文本;
i:在当前字符前插入文本;
I:在行首插入文本;
o:在当前行后面插入一空行;
O:在当前行前面插入一空行;
:wq:在命令模式下,执行存盘退出操作;
:w:在命令模式下,执行存盘操作;
:w!:在命令模式下,执行强制存盘操作;
:q:在命令模式下,执行退出vi操作;
:q!:在命令模式下,执行强制退出vi操作;
:e文件名:在命令模式下,打开并编辑指定名称的文件;
:n:在命令模式下,如果同时打开多个文件,则继续编辑下一个文件;
:f:在命令模式下,用于显示当前的文件名、光标所在行的行号以及显示比例;
:set number:在命令模式下,用于在最左端显示行号;
:set nonumber:在命令模式下,用于在最左端不显示行号;
第一部分:一般模式可用的光标移动、复制粘贴、搜索替换等
| 移动光标的方法 | |
|---|---|
| h 或 向左箭头键(←) | 光标向左移动一个字符 |
| j 或 向下箭头键(↓) | 光标向下移动一个字符 |
| k 或 向上箭头键(↑) | 光标向上移动一个字符 |
| l 或 向右箭头键(→) | 光标向右移动一个字符 |
| 如果你将右手放在键盘上的话,你会发现 hjkl 是排列在一起的,因此可以使用这四个按钮来移动光标。 如果想要进行多次移动的话,例如向下移动 30 行,可以使用 "30j" 或 "30↓" 的组合按键, 亦即加上想要进行的次数(数字)后,按下动作即可! | |
| [Ctrl] + [f] | 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) |
| [Ctrl] + [b] | 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) |
| [Ctrl] + [d] | 屏幕『向下』移动半页 |
| [Ctrl] + [u] | 屏幕『向上』移动半页 |
| + | 光标移动到非空格符的下一行 |
| - | 光标移动到非空格符的上一行 |
| n<space> | 那个 n 表示『数字』,例如 20 。按下数字后再按空格键,光标会向右移动这一行的 n 个字符。例如 20<space> 则光标会向后面移动 20 个字符距离。 |
| 0 或功能键[Home] | 这是数字『 0 』:移动到这一行的最前面字符处 (常用) |
| $ 或功能键[End] | 移动到这一行的最后面字符处(常用) |
| H | 光标移动到这个屏幕的最上方那一行的第一个字符 |
| M | 光标移动到这个屏幕的中央那一行的第一个字符 |
| L | 光标移动到这个屏幕的最下方那一行的第一个字符 |
| G | 移动到这个档案的最后一行(常用) |
| nG | n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu) |
| gg | 移动到这个档案的第一行,相当于 1G 啊! (常用) |
| n<Enter> | n 为数字。光标向下移动 n 行(常用) |
| 搜索替换 | |
| /word | 向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用) |
| ?word | 向光标之上寻找一个字符串名称为 word 的字符串。 |
| n | 这个 n 是英文按键。代表重复前一个搜寻的动作。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! |
| N | 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 |
| 使用 /word 配合 n 及 N 是非常有帮助的!可以让你重复的找到一些你搜寻的关键词! | |
| :n1,n2s/word1/word2/g | n1 与 n2 为数字。在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 !举例来说,在 100 到 200 行之间搜寻 vbird 并取代为 VBIRD 则: 『:100,200s/vbird/VBIRD/g』。(常用) |
| :1,$s/word1/word2/g 或 :%s/word1/word2/g | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !(常用) |
| :1,$s/word1/word2/gc 或 :%s/word1/word2/gc | 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给用户确认 (confirm) 是否需要取代!(常用) |
| 删除、复制与贴上 | |
| x, X | 在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) |
| nx | n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
| dd | 删除游标所在的那一整行(常用) |
| ndd | n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 (常用) |
| d1G | 删除光标所在到第一行的所有数据 |
| dG | 删除光标所在到最后一行的所有数据 |
| d$ | 删除游标所在处,到该行的最后一个字符 |
| d0 | 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
| yy | 复制游标所在的那一行(常用) |
| nyy | n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) |
| y1G | 复制游标所在行到第一行的所有数据 |
| yG | 复制游标所在行到最后一行的所有数据 |
| y0 | 复制光标所在的那个字符到该行行首的所有数据 |
| y$ | 复制光标所在的那个字符到该行行尾的所有数据 |
| p, P | p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) |
| J | 将光标所在行与下一行的数据结合成同一行 |
| c | 重复删除多个数据,例如向下删除 10 行,[ 10cj ] |
| u | 复原前一个动作。(常用) |
| [Ctrl]+r | 重做上一个动作。(常用) |
| 这个 u 与 [Ctrl]+r 是很常用的指令!一个是复原,另一个则是重做一次~ 利用这两个功能按键,你的编辑,嘿嘿!很快乐的啦! | |
| . | 不要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果你想要重复删除、重复贴上等等动作,按下小数点『.』就好了! (常用) |
第二部分:一般模式切换到编辑模式的可用的按钮说明
| 进入输入或取代的编辑模式 | |
|---|---|
| i, I | 进入输入模式(Insert mode): i 为『从目前光标所在处输入』, I 为『在目前所在行的第一个非空格符处开始输入』。 (常用) |
| a, A | 进入输入模式(Insert mode): a 为『从目前光标所在的下一个字符处开始输入』, A 为『从光标所在行的最后一个字符处开始输入』。(常用) |
| o, O | 进入输入模式(Insert mode): 这是英文字母 o 的大小写。o 为在目前光标所在的下一行处输入新的一行; O 为在目前光标所在的上一行处输入新的一行!(常用) |
| r, R | 进入取代模式(Replace mode): r 只会取代光标所在的那一个字符一次;R会一直取代光标所在的文字,直到按下 ESC 为止;(常用) |
| 上面这些按键中,在 vi 画面的左下角处会出现『--INSERT--』或『--REPLACE--』的字样。 由名称就知道该动作了吧!!特别注意的是,我们上面也提过了,你想要在档案里面输入字符时, 一定要在左下角处看到 INSERT 或 REPLACE 才能输入喔! | |
| [Esc] | 退出编辑模式,回到一般模式中(常用) |
第三部分:一般模式切换到指令行模式的可用的按钮说明
| 指令行的储存、离开等指令 | |
|---|---|
| :w | 将编辑的数据写入硬盘档案中(常用) |
| :w! | 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! |
| :q | 离开 vi (常用) |
| :q! | 若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。 |
| 注意一下啊,那个惊叹号 (!) 在 vi 当中,常常具有『强制』的意思~ | |
| :wq | 储存后离开,若为 :wq! 则为强制储存后离开 (常用) |
| ZZ | 这是大写的 Z 喔!如果修改过,保存当前文件,然后退出!效果等同于(保存并退出) |
| ZQ | 不保存,强制退出。效果等同于 :q!。 |
| :w [filename] | 将编辑的数据储存成另一个档案(类似另存新档) |
| :r [filename] | 在编辑的数据中,读入另一个档案的数据。亦即将 『filename』 这个档案内容加到游标所在行后面 |
| :n1,n2 w [filename] | 将 n1 到 n2 的内容储存成 filename 这个档案。 |
| :! command | 暂时离开 vi 到指令行模式下执行 command 的显示结果!例如 『:! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息! |
| vim 环境的变更 | |
| :set nu | 显示行号,设定之后,会在每一行的前缀显示该行的行号 |
| :set nonu | 与 set nu 相反,为取消行号! |
uniq 命令
语法
uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][--help][--version][输入文件][输出文件]
uniq [OPTION]... [INPUT [OUTPUT]]
主要用途
-
uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。
-
uniq 可检查文本文件中重复出现的行列。
参数说明:
- -c或--count 在每列旁边显示该行重复出现的次数。
- -d或--repeated 仅显示重复出现的行列。
- -f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
- -s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
- -u或--unique 仅显示出一次的行列。
- -w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
- --help 显示帮助。
- --version 显示版本信息。
- [输入文件] 指定已排序好的文本文件。如果不指定此项,则从标准读取数据;
- [输出文件] 指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
Filter adjacent matching lines from INPUT (or standard input),
writing to OUTPUT (or standard output).
实例
实例文件uniq.txt
GET managerhtml HTTP 403
GET managerhtml HTTP 403
GET managerhtml HTTP 403
GET robots.txt HTTP 302
GET login HTTP 200 4020
GET login HTTP 200 4020
GET robots.txt HTTP 302
GET login HTTP 200 4020
GET robots.txt HTTP 302
GET login HTTP 200 4020
GET robots.txt HTTP 302
GET login HTTP 200 4020
- 统计重复出现的次数,注意连续的行重复 uniq -c uniq.txt
3 GET managerhtml HTTP 403 1 GET robots.txt HTTP 302 2 GET login HTTP 200 4020 1 GET robots.txt HTTP 302 1 GET login HTTP 200 4020 1 GET robots.txt HTTP 302 1 GET login HTTP 200 4020 1 GET robots.txt HTTP 302 - 先排序然后统计出现的次数 sort uniq.txt|uniq -c
5 GET login HTTP 200 4020 3 GET managerhtml HTTP 403 4 GET robots.txt HTTP 302
sort命令
语法
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
sort [OPTION]... [FILE]...
or: sort [OPTION]... --files0-from=F
主要用途
-
sort命令用于将文本文件内容加以排序。
-
sort可针对文本文件的内容,以行为单位来排序。
参数说明:
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- --help 显示帮助。
- --version 显示版本信息。
- [-k field1[,field2]] 按指定的列进行排序。
-b, --ignore-leading-blanks ignore leading blanks
-d, --dictionary-order consider only blanks and alphanumeric characters
-f, --ignore-case fold lower case to upper case characters
-g, --general-numeric-sort compare according to general numerical value
-i, --ignore-nonprinting consider only printable characters
-M, --month-sort compare (unknown) < 'JAN' < ... < 'DEC'
-h, --human-numeric-sort compare human readable numbers (e.g., 2K 1G)
-n, --numeric-sort compare according to string numerical value
-R, --random-sort sort by random hash of keys
--random-source=FILE get random bytes from FILE
-r, --reverse reverse the result of comparisons
--sort=WORD sort according to WORD:
general-numeric -g, human-numeric -h, month -M,
numeric -n, random -R, version -V
-V, --version-sort natural sort of (version) numbers within text
Other options:
--batch-size=NMERGE merge at most NMERGE inputs at once;
for more use temp files
-c, --check, --check=diagnose-first check for sorted input; do not sort
-C, --check=quiet, --check=silent like -c, but do not report first bad line
--compress-program=PROG compress temporaries with PROG;
decompress them with PROG -d
--debug annotate the part of the line used to sort,
and warn about questionable usage to stderr
--files0-from=F read input from the files specified by
NUL-terminated names in file F;
If F is - then read names from standard input
-k, --key=KEYDEF sort via a key; KEYDEF gives location and type
-m, --merge merge already sorted files; do not sort
-o, --output=FILE write result to FILE instead of standard output
-s, --stable stabilize sort by disabling last-resort comparison
-S, --buffer-size=SIZE use SIZE for main memory buffer
-t, --field-separator=SEP use SEP instead of non-blank to blank transition
-T, --temporary-directory=DIR use DIR for temporaries, not $TMPDIR or /tmp;
multiple options specify multiple directories
--parallel=N change the number of sorts run concurrently to N
-u, --unique with -c, check for strict ordering;
without -c, output only the first of an equal run
-z, --zero-terminated end lines with 0 byte, not newline
--help display this help and exit
--version output version information and exit
实例
- 显示文件的头20行 head -n 20 file.log
look命令
look命令是在Linux和Unix系统中用于快速查找文本文件中以指定前缀开头的行的工具。主要用途是在大型文本文件中进行快速查找和检索操作,通常用于查找特定单词、术语或代码片段的起始部分。
语法
look [options] string [file]
look [options] [...]
主要用途
-
查找单词或字符串的前缀匹配。
-
用于词典文件的查找。
-
快速文本检索。
参数说明:
- -a:使用另一个字典文件web2,该文件也位于/usr/dict目录下;
- -d:只对比英文字母和数字,其余一概忽略不予比对;
- -f:忽略字符大小写差别;
- -t<字尾字符串>:设置字尾字符串。
Options:
-a, --alternative use the alternative dictionary
-d, --alphanum compare only blanks and alphanumeric characters
-f, --ignore-case ignore case differences when comparing
-t, --terminate define the string-termination character
实例
测试文件 look.txt
This is a sample text file for demonstration purposes.
It contains various words, including apple, banana, cherry, and orange.
The quick brown fox jumps over the lazy dog.
Please use the `look` command to find specific words in this text.
- 查找包含完整单词 "apple" 的行。 look apple look.txt
- 忽略大小写敏感 look -f Apple look.txt
- look china 如果不指定文件,则在/usr/share/dict/words 文件找出所有对应的单词
结果:China
china
chinaberries
chinaberry
chinafish
chinafy
Chinagraph
chinalike
Chinaman
chinaman
china-mania
chinamania
chinamaniac
Chinamen
chinamen
chinampa
Chinan
chinanta
Chinantecan
Chinantecs
chinaphthol
chinar
chinaroot
chinas
Chinatown
chinatown
chinaware
chinawoman
-
如果使用 look chinese 结果是:
Chinese
chinese
Chinese-houses
Chinesery
如果使用 look -t e chinese 则会查出来,即找出chine 开始的所有的单词chine
chined
Chinee
chinela
chinenses
chines
Chinese
chinese
Chinese-houses
Chinesery
其他命令
head命令
语法
head [参数] [文件]
head [OPTION]... [FILE]...
主要用途
-
head 命令可用于查看文件的开头部分的内容,有一个常用的参数 -n 用于显示行数,默认为 10,即显示 10 行的内容。
参数说明:
- -q 隐藏文件名
- -v 显示文件名
- -c<数目> 显示的字节数。
- -n<行数> 显示的行数
Mandatory arguments to long options are mandatory for short options too.
-c, --bytes=[-]K print the first K bytes of each file;
with the leading '-', print all but the last
K bytes of each file
-n, --lines=[-]K print the first K lines instead of the first 10;
with the leading '-', print all but the last
K lines of each file
-q, --quiet, --silent never print headers giving file names
-v, --verbose always print headers giving file names
--help display this help and exit
--version output version information and exit
K may have a multiplier suffix:
b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024,
GB 1000*1000*1000, G 1024*1024*1024, and so on for T, P, E, Z, Y.
实例
- 显示文件的头20行 head -n 20 file.log
tail命令
语法
tail [参数] [文件]
主要用途
-
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
-
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
参数说明:
- -f 循环读取
- -q 不显示处理信息
- -v 显示详细的处理信息
- -c<数目> 显示的字节数
- -n<行数> 显示文件的尾部 n 行内容
- --pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
- -q, --quiet, --silent 从不输出给出文件名的首部
- -s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
实例
-
显示日志并且刷新变化 tail -f file.log
-
显示文件的最后10行 tail -n 10 file.log
xargs命令
给其他命令传递参数的一个过滤器
语法
xargs [OPTION]... COMMAND INITIAL-ARGS...
主要用途
- xargs(英文全拼: eXtended ARGuments)是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。
- xargs 可以将管道或标准输入(stdin)数据转换成命令行参数,也能够从文件的输出中读取数据。
- xargs 也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。
- xargs 默认的命令是 echo,这意味着通过管道传递给 xargs 的输入将会包含换行和空白,不过通过 xargs 的处理,换行和空白将被空格取代。
- xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。
参数说明:
- -a file 从文件中读入作为 stdin
- -e flag ,注意有的时候可能会是-E,flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。
- -p 当每次执行一个argument的时候询问一次用户。
- -n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
- -t 表示先打印命令,然后再执行。
- -i 或者是-I,这得看linux支持了,将xargs的每项名称,一般是一行一行赋值给 {},可以用 {} 代替。
- -r no-run-if-empty 当xargs的输入为空的时候则停止xargs,不用再去执行了。
- -s num 命令行的最大字符数,指的是 xargs 后面那个命令的最大命令行字符数。
- -L num 从标准输入一次读取 num 行送给 command 命令。
- -l 同 -L。
- -d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分隔符。
- -x exit的意思,主要是配合-s使用。。
- -P 修改最大的进程数,默认是1,为0时候为as many as it can ,这个例子我没有想到,应该平时都用不到的吧。
Run COMMAND with arguments INITIAL-ARGS and more arguments read from input.
Mandatory arguments to long options are mandatory for short options too.
Non-mandatory arguments are indicated by [square brackets]
-0, --null Items are separated by a null, not whitespace.
Disables quote and backslash processing
-a, --arg-file=FILE Read arguments from FILE, not standard input
-d, --delimiter=CHARACTER Input items are separated by CHARACTER, not by
blank space. Disables quote and backslash
processing
-E END If END occurs as a line of input, the rest of
the input is ignored.
-e [END], --eof[=END] Equivalent to -E END if END is specified.
Otherwise, there is no end-of-file string
--help Print a summary of the options to xargs.
-I R same as --replace=R (R must be specified)
-i,--replace=[R] Replace R in initial arguments with names
read from standard input. If R is
unspecified, assume {}
-L,-l, --max-lines=MAX-LINES Use at most MAX-LINES nonblank input lines per
command line
-l Use at most one nonblank input line per
command line
-n, --max-args=MAX-ARGS Use at most MAX-ARGS arguments per command
line
-P, --max-procs=MAX-PROCS Run up to max-procs processes at a time
-p, --interactive Prompt before running commands
--process-slot-var=VAR Set environment variable VAR in child
processes
-r, --no-run-if-empty If there are no arguments, run no command.
If this option is not given, COMMAND will be
run at least once.
-s, --max-chars=MAX-CHARS Limit commands to MAX-CHARS at most
--show-limits Show limits on command-line length.
-t, --verbose Print commands before executing them
--version Print the version number
-x, --exit Exit if the size (see -s) is exceeded
实例
-
ps -ef | grep java | awk '{print $2}' | xargs kill -9 查询java进程并kill
系统管理
ps命令
Linux ps (英文全拼:process status)
语法
ps [options] [--help]
主要用途
-
命令用于显示当前进程的状态,类似于 windows 的任务管理器。
参数说明:
-a:显示所有终端机下执行的程序,除了阶段作业领导者之外。
a:显示现行终端机下的所有程序,包括其他用户的程序。
-A:显示所有程序。
-c:显示CLS和PRI栏位。
c:列出程序时,显示每个程序真正的指令名称,而不包含路径,选项或常驻服务的标示。
-C<指令名称>:指定执行指令的名称,并列出该指令的程序的状况。
-d:显示所有程序,但不包括阶段作业领导者的程序。
-e:此选项的效果和指定"A"选项相同。
e:列出程序时,显示每个程序所使用的环境变量。
-f:显示UID,PPIP,C与STIME栏位。
f:用ASCII字符显示树状结构,表达程序间的相互关系。
-g<群组名称>:此选项的效果和指定"-G"选项相同,当亦能使用阶段作业领导者的名称来指定。
g:显示现行终端机下的所有程序,包括群组领导者的程序。
-G<群组识别码>:列出属于该群组的程序的状况,也可使用群组名称来指定。
h:不显示标题列。
-H:显示树状结构,表示程序间的相互关系。
-j或j:采用工作控制的格式显示程序状况。
-l或l:采用详细的格式来显示程序状况。
L:列出栏位的相关信息。
-m或m:显示所有的执行绪。
n:以数字来表示USER和WCHAN栏位。
-N:显示所有的程序,除了执行ps指令终端机下的程序之外。
-p<程序识别码>:指定程序识别码,并列出该程序的状况。
p<程序识别码>:此选项的效果和指定"-p"选项相同,只在列表格式方面稍有差异。
r:只列出现行终端机正在执行中的程序。
-s<阶段作业>:指定阶段作业的程序识别码,并列出隶属该阶段作业的程序的状况。
s:采用程序信号的格式显示程序状况。
S:列出程序时,包括已中断的子程序资料。
-t<终端机编号>:指定终端机编号,并列出属于该终端机的程序的状况。
t<终端机编号>:此选项的效果和指定"-t"选项相同,只在列表格式方面稍有差异。
-T:显示现行终端机下的所有程序。
-u<用户识别码>:此选项的效果和指定"-U"选项相同。
u:以用户为主的格式来显示程序状况。
-U<用户识别码>:列出属于该用户的程序的状况,也可使用用户名称来指定。
U<用户名称>:列出属于该用户的程序的状况。
v:采用虚拟内存的格式显示程序状况。
-V或V:显示版本信息。
-w或w:采用宽阔的格式来显示程序状况。
x:显示所有程序,不以终端机来区分。
X:采用旧式的Linux i386登陆格式显示程序状况。
-y:配合选项"-l"使用时,不显示F(flag)栏位,并以RSS栏位取代ADDR栏位 。
-<程序识别码>:此选项的效果和指定"p"选项相同。
--cols<每列字符数>:设置每列的最大字符数。
--columns<每列字符数>:此选项的效果和指定"--cols"选项相同。
--cumulative:此选项的效果和指定"S"选项相同。
--deselect:此选项的效果和指定"-N"选项相同。
--forest:此选项的效果和指定"f"选项相同。
--headers:重复显示标题列。
--help:在线帮助。
--info:显示排错信息。
--lines<显示列数>:设置显示画面的列数。
--no-headers:此选项的效果和指定"h"选项相同,只在列表格式方面稍有差异。
--group<群组名称>:此选项的效果和指定"-G"选项相同。
--Group<群组识别码>:此选项的效果和指定"-G"选项相同。
--pid<程序识别码>:此选项的效果和指定"-p"选项相同。
--rows<显示列数>:此选项的效果和指定"--lines"选项相同。
--sid<阶段作业>:此选项的效果和指定"-s"选项相同。
--tty<终端机编号>:此选项的效果和指定"-t"选项相同。
--user<用户名称>:此选项的效果和指定"-U"选项相同。
--User<用户识别码>:此选项的效果和指定"-U"选项相同。
--version:此选项的效果和指定"-V"选项相同。
--widty<每列字符数>:此选项的效果和指定"-cols"选项相同。
- -A 列出所有的进程
- -w 显示加宽可以显示较多的资讯
- -au 显示较详细的资讯
- -aux 显示所有包含其他使用者的行程
-
au(x) 输出格式 :
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
- USER: 行程拥有者
- PID: pid
- %CPU: 占用的 CPU 使用率
- %MEM: 占用的记忆体使用率
- VSZ: 占用的虚拟记忆体大小
- RSS: 占用的记忆体大小
- TTY: 终端的次要装置号码 (minor device number of tty)
-
STAT: 该行程的状态:
- D: 无法中断的休眠状态 (通常 IO 的进程)
- R: 正在执行中
- S: 静止状态
- T: 暂停执行
- Z: 不存在但暂时无法消除
- W: 没有足够的记忆体分页可分配
- <: 高优先序的行程
- N: 低优先序的行程
- L: 有记忆体分页分配并锁在记忆体内 (实时系统或捱A I/O)
- START: 行程开始时间
- TIME: 执行的时间
- COMMAND:所执行的指令
Basic options:
-A, -e all processes
-a all with tty, except session leaders
a all with tty, including other users
-d all except session leaders
-N, --deselect negate selection
r only running processes
T all processes on this terminal
x processes without controlling ttys
Selection by list:
-C <command> command name
-G, --Group <GID> real group id or name
-g, --group <group> session or effective group name
-p, p, --pid <PID> process id
--ppid <PID> parent process id
-q, q, --quick-pid <PID>
process id (quick mode)
-s, --sid <session> session id
-t, t, --tty <tty> terminal
-u, U, --user <UID> effective user id or name
-U, --User <UID> real user id or name
The selection options take as their argument either:
a comma-separated list e.g. '-u root,nobody' or
a blank-separated list e.g. '-p 123 4567'
Output formats:
-F extra full
-f full-format, including command lines
f, --forest ascii art process tree
-H show process hierarchy
-j jobs format
j BSD job control format
-l long format
l BSD long format
-M, Z add security data (for SELinux)
-O <format> preloaded with default columns
O <format> as -O, with BSD personality
-o, o, --format <format>
user-defined format
s signal format
u user-oriented format
v virtual memory format
X register format
-y do not show flags, show rss vs. addr (used with -l)
--context display security context (for SELinux)
--headers repeat header lines, one per page
--no-headers do not print header at all
--cols, --columns, --width <num>
set screen width
--rows, --lines <num>
set screen height
Show threads:
H as if they were processes
-L possibly with LWP and NLWP columns
-m, m after processes
-T possibly with SPID column
Miscellaneous options:
-c show scheduling class with -l option
c show true command name
e show the environment after command
k, --sort specify sort order as: [+|-]key[,[+|-]key[,...]]
L show format specifiers
n display numeric uid and wchan
S, --cumulative include some dead child process data
-y do not show flags, show rss (only with -l)
-V, V, --version display version information and exit
-w, w unlimited output width --help <simple|list|output|threads|misc|all>
display help and exit
实例
-
查找java进程 ps -ef | grep java
- ps axo pid,comm,pcpu # 查看进程的PID、名称以及CPU 占用率
ps aux | sort -rnk 4 # 按内存资源的使用量对进程进行排序
ps aux | sort -nk 3 # 按 CPU 资源的使用量对进程进行排序
ps -A # 显示所有进程信息
ps -u root # 显示指定用户信息
ps -efL # 查看线程数
ps -e -o "%C : %p :%z : %a"|sort -k5 -nr # 查看进程并按内存使用大小排列
ps -ef # 显示所有进程信息,连同命令行
ps -ef | grep ssh # ps 与grep 常用组合用法,查找特定进程
ps -C nginx # 通过名字或命令搜索进程
ps aux --sort=-pcpu,+pmem # CPU或者内存进行排序,-降序,+升序
ps -f --forest -C nginx # 用树的风格显示进程的层次关系
ps -o pid,uname,comm -C nginx # 显示一个父进程的子进程
ps -e -o pid,uname=USERNAME,pcpu=CPU_USAGE,pmem,comm # 重定义标签
ps -e -o pid,comm,etime # 显示进程运行的时间
ps -aux | grep named # 查看named进程详细信息
ps -o command -p 91730 | sed -n 2p # 通过进程id获取服务名称
top命令
语法
top [-] [d delay] [q] [c] [S] [s] [i] [n] [b]
top -hv | -bcHiOSs -d secs -n max -u|U user -p pid(s) -o field -w [cols]
主要用途
-
Linux top命令用于实时显示 process 的动态。
参数说明:
- d : 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s
- q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行
- c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称
- S : 累积模式,会将己完成或消失的子进程 ( dead child process ) 的 CPU time 累积起来
- s : 安全模式,将交谈式指令取消, 避免潜在的危机
- i : 不显示任何闲置 (idle) 或无用 (zombie) 的进程
- n : 更新的次数,完成后将会退出 top
- b : 批次档模式,搭配 "n" 参数一起使用,可以用来将 top 的结果输出到档案内
-
-b:以批处理模式操作;
-c:显示完整的治命令;
-d:屏幕刷新间隔时间;
-I:忽略失效过程;
-s:保密模式;
-S:累积模式;
-i<时间>:设置间隔时间;
-u<用户名>:指定用户名;
-p<进程号>:指定进程;
-n<次数>:循环显示的次数
实例
1. top -p 139 指定进程
2. top
top - 12:19:54 up 293 days, 22:41, 1 user, load average: 0.85, 0.72, 0.82
依次对应:系统当前时间 up 系统到目前为止i运行的时间, 当前登陆系统的用户数量, load average后面的三个数字分别表示距离现在一分钟,五分钟,十五分钟的负载情况。
这行信息与命令uptime显示的信息相同
注意:load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
Tasks: 76 total, 1 running, 75 sleeping, 0 stopped, 0 zombie
依次对应:tasks表示任务(进程),240 total则表示现在有240个进程,其中处于运行中的有2个,238个在休眠(挂起),stopped状态即停止的进程数为0,zombie状态即僵尸的进程数为0个。
%Cpu(s): 1.0 us, 0.7 sy, 0.0 ni, 98.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
us:user 用户空间占用cpu的百分比
sy:system 内核空间占用cpu的百分比
ni:niced 改变过优先级的进程占用cpu的百分比
id:idle空闲cpu百分比
wa:IO wait IO等待占用cpu的百分比
hi:Hardware IRQ 硬中断 占用cpu的百分比
si:software 软中断 占用cpu的百分比
st:被hypervisor偷去的时间
KiB Mem : 1882012 total, 90948 free, 734120 used, 1056944 buff/cache
依次对应:物理内存总量(3.7G),空闲内存总量(2.5G),使用中的内存总量(2.4G),缓冲内存量
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心
KiB Swap: 0 total, 0 free, 0 used. 959848 avail Mem
依次对应:交换区总量(4G),空闲交换区总量(2.7G),使用的交换区总量(1.2G),可用交换取总量
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10630 root 20 0 960544 34916 15572 S 0.7 1.9 33:57.63 YDService
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
磁盘管理
df命令
显示磁盘的相关信息
语法
df [选项]... [FILE]...
主要用途
-
用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
参数说明:
- 文件-a, --all 包含所有的具有 0 Blocks 的文件系统
- 文件--block-size={SIZE} 使用 {SIZE} 大小的 Blocks
- 文件-h, --human-readable 使用人类可读的格式(预设值是不加这个选项的...)
- 文件-H, --si 很像 -h, 但是用 1000 为单位而不是用 1024
- 文件-i, --inodes 列出 inode 资讯,不列出已使用 block
- 文件-k, --kilobytes 就像是 --block-size=1024
- 文件-l, --local 限制列出的文件结构
- 文件-m, --megabytes 就像 --block-size=1048576
- 文件--no-sync 取得资讯前不 sync (预设值)
- 文件-P, --portability 使用 POSIX 输出格式
- 文件--sync 在取得资讯前 sync
- 文件-t, --type=TYPE 限制列出文件系统的 TYPE
- 文件-T, --print-type 显示文件系统的形式
- 文件-x, --exclude-type=TYPE 限制列出文件系统不要显示 TYPE
- 文件-v (忽略)
- 文件--help 显示这个帮手并且离开
- 文件--version 输出版本资讯并且离开
-a, --all include pseudo, duplicate, inaccessible file systems
-B, --block-size=SIZE scale sizes by SIZE before printing them; e.g.,
'-BM' prints sizes in units of 1,048,576 bytes;
see SIZE format below
--direct show statistics for a file instead of mount point
--total produce a grand total
-h, --human-readable print sizes in human readable format (e.g., 1K 234M 2G)
-H, --si likewise, but use powers of 1000 not 1024
-i, --inodes list inode information instead of block usage
-k like --block-size=1K
-l, --local limit listing to local file systems
--no-sync do not invoke sync before getting usage info (default)
--output[=FIELD_LIST] use the output format defined by FIELD_LIST,
or print all fields if FIELD_LIST is omitted.
-P, --portability use the POSIX output format
--sync invoke sync before getting usage info
-t, --type=TYPE limit listing to file systems of type TYPE
-T, --print-type print file system type
-x, --exclude-type=TYPE limit listing to file systems not of type TYPE
-v (ignored)
--help display this help and exit
--version output version information and exit
Display values are in units of the first available SIZE from --block-size,
and the DF_BLOCK_SIZE, BLOCK_SIZE and BLOCKSIZE environment variables.
Otherwise, units default to 1024 bytes (or 512 if POSIXLY_CORRECT is set).
SIZE is an integer and optional unit (example: 10M is 10*1024*1024). Units
are K, M, G, T, P, E, Z, Y (powers of 1024) or KB, MB, ... (powers of 1000).
FIELD_LIST is a comma-separated list of columns to be included. Valid
field names are: 'source', 'fstype', 'itotal', 'iused', 'iavail', 'ipcent',
'size', 'used', 'avail', 'pcent', 'file' and 'target' (see info page).
实例
- df 显示文件系统的磁盘使用情况
- df -T 列出文件系统的类型
- df -t ext4 列出 类型是ext4的磁盘信息
- df -lh 已易读的方式显示本地分区磁盘使用率
du命令
du (英文全拼:disk usage)命令用于显示目录或文件的大小。
语法
du [-abcDhHklmsSx][-L <符号连接>][-X <文件>][--block-size][--exclude=<目录或文件>][--max-depth=<目录层数>][--help][--version][目录或文件]
主要用途
-
显示指定的目录或文件所占用的磁盘空间。
参数说明:
- -a或-all 显示目录中个别文件的大小。
- -b或-bytes 显示目录或文件大小时,以byte为单位。
- -c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
- -D或--dereference-args 显示指定符号连接的源文件大小。
- -h或--human-readable 以K,M,G为单位,提高信息的可读性。
- -H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
- -k或--kilobytes 以1024 bytes为单位。
- -l或--count-links 重复计算硬件连接的文件。
- -L<符号连接>或--dereference<符号连接> 显示选项中所指定符号连接的源文件大小。
- -m或--megabytes 以1MB为单位。
- -s或--summarize 仅显示总计。
- -S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
- -x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
- -X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
- --exclude=<目录或文件> 略过指定的目录或文件。
- --max-depth=<目录层数> 超过指定层数的目录后,予以忽略。
- --help 显示帮助。
- --version 显示版本信息。
-0, --null end each output line with 0 byte rather than newline
-a, --all write counts for all files, not just directories
--apparent-size print apparent sizes, rather than disk usage; although
the apparent size is usually smaller, it may be
larger due to holes in ('sparse') files, internal
fragmentation, indirect blocks, and the like
-B, --block-size=SIZE scale sizes by SIZE before printing them; e.g.,
'-BM' prints sizes in units of 1,048,576 bytes;
see SIZE format below
-b, --bytes equivalent to '--apparent-size --block-size=1'
-c, --total produce a grand total
-D, --dereference-args dereference only symlinks that are listed on the
command line
-d, --max-depth=N print the total for a directory (or file, with --all)
only if it is N or fewer levels below the command
line argument; --max-depth=0 is the same as
--summarize
--files0-from=F summarize disk usage of the
NUL-terminated file names specified in file F;
if F is -, then read names from standard input
-H equivalent to --dereference-args (-D)
-h, --human-readable print sizes in human readable format (e.g., 1K 234M 2G)
--inodes list inode usage information instead of block usage
-k like --block-size=1K
-L, --dereference dereference all symbolic links
-l, --count-links count sizes many times if hard linked
-m like --block-size=1M
-P, --no-dereference don't follow any symbolic links (this is the default)
-S, --separate-dirs for directories do not include size of subdirectories
--si like -h, but use powers of 1000 not 1024
-s, --summarize display only a total for each argument
-t, --threshold=SIZE exclude entries smaller than SIZE if positive,
or entries greater than SIZE if negative
--time show time of the last modification of any file in the
directory, or any of its subdirectories
--time=WORD show time as WORD instead of modification time:
atime, access, use, ctime or status
--time-style=STYLE show times using STYLE, which can be:
full-iso, long-iso, iso, or +FORMAT;
FORMAT is interpreted like in 'date'
-X, --exclude-from=FILE exclude files that match any pattern in FILE
--exclude=PATTERN exclude files that match PATTERN
-x, --one-file-system skip directories on different file systems
--help display this help and exit
--version output version information and exit
Display values are in units of the first available SIZE from --block-size,
and the DU_BLOCK_SIZE, BLOCK_SIZE and BLOCKSIZE environment variables.
Otherwise, units default to 1024 bytes (or 512 if POSIXLY_CORRECT is set).
SIZE is an integer and optional unit (example: 10M is 10*1024*1024). Units
are K, M, G, T, P, E, Z, Y (powers of 1024) or KB, MB, ... (powers of 1000).
示例
- du -sh /home/* 显示home下的每个文件夹下占用磁盘的总和
- du -h info.log 显示info.log占用的大小
- du -h --max-depth=3 . / 显示当前目录下最多三层的文件占用磁盘信息
Linux tree命令
树状图列出目录的内容。默认情况下,它会从当前目录开始列出所有文件。如果指定了目录参数,则会依次列出给定目录中找到的所有文件或目录。它将目录显示为分支,将文件显示为叶子,使用户可以轻松地可视化给定路径内的文件和目录的组织结构。
语法
tree [选项] [目录]
usage: tree [-acdfghilnpqrstuvxACDFJQNSUX] [-H baseHREF] [-T title ]
[-L level [-R]] [-P pattern] [-I pattern] [-o filename] [--version]
[--help] [--inodes] [--device] [--noreport] [--nolinks] [--dirsfirst]
[--charset charset] [--filelimit[=]#] [--si] [--timefmt[=]<f>]
[--sort[=]<name>] [--matchdirs] [--ignore-case] [--] [<directory list>]
主要用途
-
查看目录结构
-
查找特定文件或目录
-
计算目录中文件的总数和大小。
参数说明:
-
------- Listing options -------
-
-a All files are listed.
-
-d List directories only.
-
-l Follow symbolic links like directories.
-
-f Print the full path prefix for each file.
-
-x Stay on current filesystem only.
-
-L level Descend only level directories deep.
-
-R Rerun tree when max dir level reached.
-
-P pattern List only those files that match the pattern given.
-
-I pattern Do not list files that match the given pattern.
-
--ignore-case Ignore case when pattern matching.
-
--matchdirs Include directory names in -P pattern matching.
-
--noreport Turn off file/directory count at end of tree listing.
-
--charset X Use charset X for terminal/HTML and indentation line output.
-
--filelimit # Do not descend dirs with more than # files in them.
-
--timefmt <f> Print and format time according to the format <f>.
-
-o filename Output to file instead of stdout.
-
--du Print directory sizes.
-
--prune Prune empty directories from the output.
-
-------- File options ---------
-
-q Print non-printable characters as '?'.
-
-N Print non-printable characters as is.
-
-Q Quote filenames with double quotes.
-
-p Print the protections for each file.
-
-u Displays file owner or UID number.
-
-g Displays file group owner or GID number.
-
-s Print the size in bytes of each file.
-
-h Print the size in a more human readable way.
-
--si Like -h, but use in SI units (powers of 1000).
-
-D Print the date of last modification or (-c) status change.
-
-F Appends '/', '=', '*', '@', '|' or '>' as per ls -F.
-
--inodes Print inode number of each file.
-
--device Print device ID number to which each file belongs.
-
------- Sorting options -------
-
-v Sort files alphanumerically by version.
-
-t Sort files by last modification time.
-
-c Sort files by last status change time.
-
-U Leave files unsorted.
-
-r Reverse the order of the sort.
-
--dirsfirst List directories before files (-U disables).
-
--sort X Select sort: name,version,size,mtime,ctime.
-
------- Graphics options ------
-
-i Don't print indentation lines.
-
-A Print ANSI lines graphic indentation lines.
-
-S Print with CP437 (console) graphics indentation lines.
-
-n Turn colorization off always (-C overrides).
-
-C Turn colorization on always.
-
------- XML/HTML/JSON options -------
-
-X Prints out an XML representation of the tree.
-
-J Prints out an JSON representation of the tree.
-
-H baseHREF Prints out HTML format with baseHREF as top directory.
-
-T string Replace the default HTML title and H1 header with string.
-
--nolinks Turn off hyperlinks in HTML output.
-
---- Miscellaneous options ----
-
--version Print version and exit.
-
--help Print usage and this help message and exit.
-
-- Options processing terminator.
-
-a 或 --all 显示所有文件和目录,包括隐藏文件和目录。
-
-d 或 --dirs-only 只显示目录。
-
-f 或 --full-path 显示每个文件的完整路径前缀。
-
-i 或 --ignore-case 在对文件名进行排序时忽略大小写。
-
-x 仅限当前文件系统,与 find -xdev 相同。
-
-I 不列出与通配符模式匹配的文件。
-
-p 或 --prune 列出权限标识。
-
--filelimit # 不遍历包含超过 # 个条目的目录。
-
-t 按最后修改时间而不是按字母顺序排序输出。
-
--noreport 在树形结构的末尾省略文件和目录报告的打印。
-
-s 与文件名一起打印每个文件的大小。
-
-u 打印文件的用户名或 UID #(如果没有用户名)
-
-g 打印文件的组名或 GID #(如果没有组名)
-
-D 打印列出的文件的最后修改时间的日期。
-
--inodes 打印文件或目录的 inode 号。
-
--device 打印文件或目录所属的设备号。
-
-F 为目录追加 /,为套接字文件追加 =,为可执行文件追加 *,为 FIFO 追加 `
-
-q 将文件名中的非打印字符打印为问号,而不是默认的脱字符表示法。
-
-N 将非打印字符按原样打印,而不是默认的脱字符表示法。
-
-r 按字母顺序的反向顺序排序输出。
-
--dirsfirst 在文件之前列出目录。
-
-n 始终关闭着色,由 -C 选项覆盖。
-
-C 始终打开着色,如果未设置 LS_COLORS 环境变量,则使用内置颜色默认值。
实例
-
列出指定目录的目录结构:
tree /home/tree -
列出指定目录的目录结构,包括隐藏文件和目录:
tree -a /home/tree -
列出指定目录的目录结构,只显示目录:
tree -d /home/tree -
列出指定目录的目录结构,包括文件的完整路径前缀:
tree -f /path/to/directory -
列出指定目录的目录结构,按照文件的最后修改时间排序:
tree -t /path/to/directory -
列出指定目录的目录结构,只显示第一级文件名:
tree -L 1 /home/tree -
不显示超过两个文件或目录的目录
tree --filelimit 2 /home/tree(如果超过2,则显示/home/tree [3 entries exceeds filelimit, not opening dir]) -
只显示目录下匹配f开头的文件,目录会正常显示,
tree -P 'f*' /home/tree
pwd命令
pwd 命令是 print working directory 的缩写,用于打印当前工作目录的路径,从根目录开始
语法
pwd [OPTIONS]
主要用途
-
打印当前工作目录的路径,从根目录开始
参数说明:
- -L print the value of $PWD if it names the current working directory
- -P print the physical directory, without any symbolic links
- -L 打印符号路径
- -P 打印实际路径
实例
-
打印当前目录 :pwd
-
mkdir pwd1
ln -s /home/linux/pwd1 /home/linux/pwd2
cd pwd2pwd -P 将显示(/home/linux/pwd1)
文件传输
ftp命令
用来设置文件系统相关功能
语法
ftp [-dignv][主机名称或IP地址]
主要用途
-
ftp命令 用来设置文件系统相关功能。ftp服务器在网上较为常见,Linux ftp命令的功能是用命令的方式来控制在本地机和远程机之间传送文件,这里详细介绍Linux ftp命令的一些经常使用的命令,相信掌握了这些使用Linux进行ftp操作将会非常容易。
参数说明:
- -d 详细显示指令执行过程,便于排错或分析程序执行的情形。
- -i 关闭互动模式,不询问任何问题。
- -g 关闭本地主机文件名称支持特殊字符的扩充特性。
- -n 不使用自动登陆。
- -v 显示指令执行过程。
Usage: { ftp | pftp } [-Apinegvtd] [hostname]
-A: enable active mode
-p: enable passive mode (default for ftp and pftp)
-i: turn off prompting during mget
-n: inhibit auto-login
-e: disable readline support, if present
-g: disable filename globbing
-m: don't force data channel interface to the same as control channel
-v: verbose mode
-t: enable packet tracing [nonfunctional]
-d: enable debugging
实例
ftp> ascii # 设定以ASCII方式传送文件(缺省值)
ftp> bell # 每完成一次文件传送,报警提示.
ftp> binary # 设定以二进制方式传送文件.
ftp> bye # 终止主机FTP进程,并退出FTP管理方式.
ftp> case # 当为ON时,用MGET命令拷贝的文件名到本地机器中,全部转换为小写字母.
ftp> cd # 同UNIX的CD命令.
ftp> cdup # 返回上一级目录.
ftp> chmod # 改变远端主机的文件权限.
ftp> close # 终止远端的FTP进程,返回到FTP命令状态, 所有的宏定义都被删除.
ftp> delete # 删除远端主机中的文件.
ftp> dir [remote-directory] [local-file] # 列出当前远端主机目录中的文件.如果有本地文件,就将结果写至本地文件.
ftp> get [remote-file] [local-file] # 从远端主机中传送至本地主机中.
ftp> help [command] # 输出命令的解释.
ftp> lcd # 改变当前本地主机的工作目录,如果缺省,就转到当前用户的HOME目录.
ftp> ls [remote-directory] [local-file] # 同DIR.
ftp> macdef # 定义宏命令.
ftp> mdelete [remote-files] # 删除一批文件.
ftp> mget [remote-files] # 从远端主机接收一批文件至本地主机.
ftp> mkdir directory-name # 在远端主机中建立目录.
ftp> mput local-files # 将本地主机中一批文件传送至远端主机.
ftp> open host [port] # 重新建立一个新的连接.
ftp> prompt # 交互提示模式.
ftp> put local-file [remote-file] # 将本地一个文件传送至远端主机中.
ftp> pwd # 列出当前远端主机目录.
ftp> quit # 同BYE.
ftp> recv remote-file [local-file] # 同GET.
ftp> rename [from] [to] # 改变远端主机中的文件名.
ftp> rmdir directory-name # 删除远端主机中的目录.
ftp> send local-file [remote-file] # 同PUT.
ftp> status # 显示当前FTP的状态.
ftp> system # 显示远端主机系统类型.
ftp> user user-name [password] [account] # 重新以别的用户名登录远端主机.
ftp> ? [command] # 同HELP. [command]指定需要帮助的命令名称。如果没有指定 command,ftp 将显示全部命令的列表。
ftp> ! # 从 ftp 子系统退出到外壳。
系统设置
ulimit命令
用于查看和设置用户对系统资源的限制的命令。它允许你在 Linux 系统上管理各种资源的限制,如文件描述符数量、内存使用量、CPU 时间等。
语法
ulimit [-SHabcdefiklmnpqrstuvxPT] [limit]
主要用途
- 管理和控制用户对系统资源的限制
参数说明:
- -S use the `soft' resource limit
- -H use the `hard' resource limit
- -a all current limits are reported
- -b the socket buffer size
- -c the maximum size of core files created
- -d the maximum size of a process's data segment
- -e the maximum scheduling priority (`nice')
- -f the maximum size of files written by the shell and its children
- -i the maximum number of pending signals
- -k the maximum number of kqueues allocated for this process
- -l the maximum size a process may lock into memory
- -m the maximum resident set size
- -n the maximum number of open file descriptors
- -p the pipe buffer size
- -q the maximum number of bytes in POSIX message queues
- -r the maximum real-time scheduling priority
- -s the maximum stack size
- -t the maximum amount of cpu time in seconds
- -u the maximum number of user processes
- -v the size of virtual memory
- -x the maximum number of file locks
- -P the maximum number of pseudoterminals
- -T the maximum number of threads
- -S:使用“软”资源限制。
- -H:使用“硬”资源限制。
- -a:报告所有当前限制。
- -b:套接字缓冲区大小。
- -c:核心文件的最大大小。
- -d:进程数据段的最大长度。
- -e:最大调度优先级(nice)。
- -f:由 shell 及其子进程写入的文件的最大大小。
- -i:挂起信号的最大数量。
- -k:为此进程分配的 kqueue 的最大数量。
- -l:进程可以锁定到内存中的最大大小。
- -m:最大驻留集大小。
- -n:打开文件描述符的最大数量。
- -p:管道缓冲区大小。
- -q:POSIX 消息队列中的最大字节数。
- -r:最大实时调度优先级。
- -s:最大栈大小。
- -t:CPU 时间的最大量(秒)。
- -u:用户进程的最大数量。
- -v:虚拟内存的大小。
- -x:文件锁的最大数量。
- -P:伪终端的最大数量。
- -T:线程的最大数量。
实例
-
解压缩文件到当前目录 unzip filename.zip -
解压缩文件到指定目录 unzip filename.zip -d /directory -
查看压缩文件内容 unzip -l filename.zip -
解压缩带密码的文件 unzip -P your_password filename.zip
小写金额(¥):
大写金额:
国家/地区(来源:https://restcountries.com)
| 中文名 | 英文名 | 简称 | 大洲 | 区域 | 人口 |
|---|---|---|---|---|---|
 阿鲁巴
阿鲁巴
|
Aruba | ABW | North America | Caribbean | 103000 |
 阿富汗
阿富汗
|
Afghanistan | AFG | Asia | Southern and Central Asia | 22720000 |
 安哥拉
安哥拉
|
Angola | AGO | Africa | Central Africa | 12878000 |
 安圭拉
安圭拉
|
Anguilla | AIA | North America | Caribbean | 8000 |
 奥兰群岛
奥兰群岛
|
Åland Islands | ALA | Europe | Northern Europe | 29458 |
 阿尔巴尼亚
阿尔巴尼亚
|
Albania | ALB | Europe | Southern Europe | 3401200 |
 安道尔
安道尔
|
Andorra | AND | Europe | Southern Europe | 78000 |
|
|
Netherlands Antilles | ANT | North America | Caribbean | 217000 |
 阿联酋
阿联酋
|
United Arab Emirates | ARE | Asia | Middle East | 2441000 |
 阿根廷
阿根廷
|
Argentina | ARG | South America | South America | 37032000 |
 亚美尼亚
亚美尼亚
|
Armenia | ARM | Asia | Middle East | 3520000 |
 美属萨摩亚
美属萨摩亚
|
American Samoa | ASM | Oceania | Polynesia | 68000 |
 南极洲
南极洲
|
Antarctica | ATA | Antarctica | Antarctica | 0 |
 法属南部领地
法属南部领地
|
French Southern territories | ATF | Antarctica | Antarctica | 0 |
 安提瓜与巴布达
安提瓜与巴布达
|
Antigua and Barbuda | ATG | North America | Caribbean | 68000 |
 澳大利亚
澳大利亚
|
Australia | AUS | Oceania | Australia and New Zealand | 18886000 |
 奥地利
奥地利
|
Austria | AUT | Europe | Western Europe | 8091800 |
 阿塞拜疆
阿塞拜疆
|
Azerbaijan | AZE | Asia | Middle East | 7734000 |
 布隆迪
布隆迪
|
Burundi | BDI | Africa | Eastern Africa | 6695000 |
 比利时
比利时
|
Belgium | BEL | Europe | Western Europe | 10239000 |
 贝宁
贝宁
|
Benin | BEN | Africa | Western Africa | 6097000 |
 荷蘭加勒比區
荷蘭加勒比區
|
Caribbean Netherlands | BES | Americas | Caribbean | 25987 |
 布基纳法索
布基纳法索
|
Burkina Faso | BFA | Africa | Western Africa | 11937000 |
 孟加拉
孟加拉
|
Bangladesh | BGD | Asia | Southern and Central Asia | 129155000 |
 保加利亚
保加利亚
|
Bulgaria | BGR | Europe | Eastern Europe | 8190900 |
 巴林
巴林
|
Bahrain | BHR | Asia | Middle East | 617000 |
 巴哈马
巴哈马
|
Bahamas | BHS | North America | Caribbean | 307000 |
 波斯尼亚和黑塞哥维那
波斯尼亚和黑塞哥维那
|
Bosnia and Herzegovina | BIH | Europe | Southern Europe | 3972000 |
 圣巴泰勒米
圣巴泰勒米
|
Saint Barthélemy | BLM | Americas | Caribbean | 4255 |
 白俄罗斯
白俄罗斯
|
Belarus | BLR | Europe | Eastern Europe | 10236000 |
 伯利兹
伯利兹
|
Belize | BLZ | North America | Central America | 241000 |
 百慕大
百慕大
|
Bermuda | BMU | North America | North America | 65000 |
 玻利维亚
玻利维亚
|
Bolivia | BOL | South America | South America | 8329000 |
 巴西
巴西
|
Brazil | BRA | South America | South America | 170115000 |
 巴巴多斯
巴巴多斯
|
Barbados | BRB | North America | Caribbean | 270000 |
 文莱
文莱
|
Brunei | BRN | Asia | Southeast Asia | 328000 |
 不丹
不丹
|
Bhutan | BTN | Asia | Southern and Central Asia | 2124000 |
 布维岛
布维岛
|
Bouvet Island | BVT | Antarctica | Antarctica | 0 |
 博茨瓦纳
博茨瓦纳
|
Botswana | BWA | Africa | Southern Africa | 1622000 |
 中非共和国
中非共和国
|
Central African Republic | CAF | Africa | Central Africa | 3615000 |
 加拿大
加拿大
|
Canada | CAN | North America | North America | 31147000 |
 科科斯群岛
科科斯群岛
|
Cocos (Keeling) Islands | CCK | Oceania | Australia and New Zealand | 600 |
 瑞士
瑞士
|
Switzerland | CHE | Europe | Western Europe | 7160400 |
 智利
智利
|
Chile | CHL | South America | South America | 15211000 |
 中国
中国
|
China | CHN | Asia | Eastern Asia | 1277558000 |
 科特迪瓦
科特迪瓦
|
Côte d’Ivoire | CIV | Africa | Western Africa | 14786000 |
 喀麦隆
喀麦隆
|
Cameroon | CMR | Africa | Central Africa | 15085000 |
 刚果民主共和国
刚果民主共和国
|
Congo, The Democratic Republic of the | COD | Africa | Central Africa | 51654000 |
 刚果
刚果
|
Congo | COG | Africa | Central Africa | 2943000 |
 库克群岛
库克群岛
|
Cook Islands | COK | Oceania | Polynesia | 20000 |
 哥伦比亚
哥伦比亚
|
Colombia | COL | South America | South America | 42321000 |
 科摩罗
科摩罗
|
Comoros | COM | Africa | Eastern Africa | 578000 |
 佛得角
佛得角
|
Cape Verde | CPV | Africa | Western Africa | 428000 |
 哥斯达黎加
哥斯达黎加
|
Costa Rica | CRI | North America | Central America | 4023000 |
 古巴
古巴
|
Cuba | CUB | North America | Caribbean | 11201000 |
 库拉索
库拉索
|
Curaçao | CUW | Americas | Caribbean | 155014 |
 圣诞岛
圣诞岛
|
Christmas Island | CXR | Oceania | Australia and New Zealand | 2500 |
 开曼群岛
开曼群岛
|
Cayman Islands | CYM | North America | Caribbean | 38000 |
 塞浦路斯
塞浦路斯
|
Cyprus | CYP | Asia | Middle East | 754700 |
 捷克
捷克
|
Czech Republic | CZE | Europe | Eastern Europe | 10278100 |
 德国
德国
|
Germany | DEU | Europe | Western Europe | 82164700 |
 吉布提
吉布提
|
Djibouti | DJI | Africa | Eastern Africa | 638000 |
 多米尼克
多米尼克
|
Dominica | DMA | North America | Caribbean | 71000 |
 丹麦
丹麦
|
Denmark | DNK | Europe | Nordic Countries | 5330000 |
 多米尼加
多米尼加
|
Dominican Republic | DOM | North America | Caribbean | 8495000 |
 阿尔及利亚
阿尔及利亚
|
Algeria | DZA | Africa | Northern Africa | 31471000 |
 厄瓜多尔
厄瓜多尔
|
Ecuador | ECU | South America | South America | 12646000 |
 埃及
埃及
|
Egypt | EGY | Africa | Northern Africa | 68470000 |
 厄立特里亚
厄立特里亚
|
Eritrea | ERI | Africa | Eastern Africa | 3850000 |
 西撒哈拉
西撒哈拉
|
Western Sahara | ESH | Africa | Northern Africa | 293000 |
 西班牙
西班牙
|
Spain | ESP | Europe | Southern Europe | 39441700 |
 爱沙尼亚
爱沙尼亚
|
Estonia | EST | Europe | Baltic Countries | 1439200 |
 埃塞俄比亚
埃塞俄比亚
|
Ethiopia | ETH | Africa | Eastern Africa | 62565000 |
 芬兰
芬兰
|
Finland | FIN | Europe | Nordic Countries | 5171300 |
 斐济岛
斐济岛
|
Fiji Islands | FJI | Oceania | Melanesia | 817000 |
 马尔维纳斯群岛
马尔维纳斯群岛
|
Falkland Islands | FLK | South America | South America | 2000 |
 法国
法国
|
France | FRA | Europe | Western Europe | 59225700 |
 法罗群岛
法罗群岛
|
Faroe Islands | FRO | Europe | Nordic Countries | 43000 |
 密克罗尼西亚联邦
密克罗尼西亚联邦
|
Micronesia, Federated States of | FSM | Oceania | Micronesia | 119000 |
 加蓬
加蓬
|
Gabon | GAB | Africa | Central Africa | 1226000 |
 英国
英国
|
United Kingdom | GBR | Europe | British Islands | 59623400 |
 格鲁吉亚
格鲁吉亚
|
Georgia | GEO | Asia | Middle East | 4968000 |
 根西岛
根西岛
|
Guernsey | GGY | Europe | Northern Europe | 62999 |
 加纳
加纳
|
Ghana | GHA | Africa | Western Africa | 20212000 |
 直布罗陀
直布罗陀
|
Gibraltar | GIB | Europe | Southern Europe | 25000 |
 几内亚
几内亚
|
Guinea | GIN | Africa | Western Africa | 7430000 |
 瓜德罗普岛
瓜德罗普岛
|
Guadeloupe | GLP | North America | Caribbean | 456000 |
 冈比亚
冈比亚
|
Gambia | GMB | Africa | Western Africa | 1305000 |
 几内亚比绍
几内亚比绍
|
Guinea-Bissau | GNB | Africa | Western Africa | 1213000 |
 赤道几内亚
赤道几内亚
|
Equatorial Guinea | GNQ | Africa | Central Africa | 453000 |
 希腊
希腊
|
Greece | GRC | Europe | Southern Europe | 10545700 |
 格林纳达
格林纳达
|
Grenada | GRD | North America | Caribbean | 94000 |
 格陵兰
格陵兰
|
Greenland | GRL | North America | North America | 56000 |
 危地马拉
危地马拉
|
Guatemala | GTM | North America | Central America | 11385000 |
 法属圭亚那
法属圭亚那
|
French Guiana | GUF | South America | South America | 181000 |
 关岛
关岛
|
Guam | GUM | Oceania | Micronesia | 168000 |
 圭亚那
圭亚那
|
Guyana | GUY | South America | South America | 861000 |
 香港(中华人民共和国特别行政区)
香港(中华人民共和国特别行政区)
|
Hong Kong | HKG | Asia | Eastern Asia | 6782000 |
 赫德岛和麦克唐纳群岛
赫德岛和麦克唐纳群岛
|
Heard Island and McDonald Islands | HMD | Antarctica | Antarctica | 0 |
 洪都拉斯
洪都拉斯
|
Honduras | HND | North America | Central America | 6485000 |
 克罗地亚
克罗地亚
|
Croatia | HRV | Europe | Southern Europe | 4473000 |
 海地
海地
|
Haiti | HTI | North America | Caribbean | 8222000 |
 匈牙利
匈牙利
|
Hungary | HUN | Europe | Eastern Europe | 10043200 |
 印尼
印尼
|
Indonesia | IDN | Asia | Southeast Asia | 212107000 |
 马恩岛
马恩岛
|
Isle of Man | IMN | Europe | Northern Europe | 85032 |
 印度
印度
|
India | IND | Asia | Southern and Central Asia | 1013662000 |
 英属印度洋领地
英属印度洋领地
|
British Indian Ocean Territory | IOT | Africa | Eastern Africa | 0 |
 爱尔兰
爱尔兰
|
Ireland | IRL | Europe | British Islands | 3775100 |
 伊朗
伊朗
|
Iran | IRN | Asia | Southern and Central Asia | 67702000 |
 伊拉克
伊拉克
|
Iraq | IRQ | Asia | Middle East | 23115000 |
 冰岛
冰岛
|
Iceland | ISL | Europe | Nordic Countries | 279000 |
 以色列
以色列
|
Israel | ISR | Asia | Middle East | 6217000 |
 意大利
意大利
|
Italy | ITA | Europe | Southern Europe | 57680000 |
 牙买加
牙买加
|
Jamaica | JAM | North America | Caribbean | 2583000 |
 泽西岛
泽西岛
|
Jersey | JEY | Europe | Northern Europe | 100800 |
 乔丹
乔丹
|
Jordan | JOR | Asia | Middle East | 5083000 |
 日本
日本
|
Japan | JPN | Asia | Eastern Asia | 126714000 |
 哈萨克斯坦
哈萨克斯坦
|
Kazakstan | KAZ | Asia | Southern and Central Asia | 16223000 |
 肯尼亚
肯尼亚
|
Kenya | KEN | Africa | Eastern Africa | 30080000 |
 吉尔吉斯斯坦
吉尔吉斯斯坦
|
Kyrgyzstan | KGZ | Asia | Southern and Central Asia | 4699000 |
 柬埔寨
柬埔寨
|
Cambodia | KHM | Asia | Southeast Asia | 11168000 |
 基里巴斯
基里巴斯
|
Kiribati | KIR | Oceania | Micronesia | 83000 |
 圣基茨和尼维斯
圣基茨和尼维斯
|
Saint Kitts and Nevis | KNA | North America | Caribbean | 38000 |
 韩国
韩国
|
South Korea | KOR | Asia | Eastern Asia | 46844000 |
 科威特
科威特
|
Kuwait | KWT | Asia | Middle East | 1972000 |
 老挝
老挝
|
Laos | LAO | Asia | Southeast Asia | 5433000 |
 黎巴嫩
黎巴嫩
|
Lebanon | LBN | Asia | Middle East | 3282000 |
 利比里亚
利比里亚
|
Liberia | LBR | Africa | Western Africa | 3154000 |
 大阿拉伯利比亚人民社会主义民众国
大阿拉伯利比亚人民社会主义民众国
|
Libyan Arab Jamahiriya | LBY | Africa | Northern Africa | 5605000 |
 圣卢西亚
圣卢西亚
|
Saint Lucia | LCA | North America | Caribbean | 154000 |
 列支敦士登
列支敦士登
|
Liechtenstein | LIE | Europe | Western Europe | 32300 |
 斯里兰卡
斯里兰卡
|
Sri Lanka | LKA | Asia | Southern and Central Asia | 18827000 |
 莱索托
莱索托
|
Lesotho | LSO | Africa | Southern Africa | 2153000 |
 立陶宛
立陶宛
|
Lithuania | LTU | Europe | Baltic Countries | 3698500 |
 卢森堡
卢森堡
|
Luxembourg | LUX | Europe | Western Europe | 435700 |
 拉脱维亚
拉脱维亚
|
Latvia | LVA | Europe | Baltic Countries | 2424200 |
 澳门(中华人民共和国特别行政区)
澳门(中华人民共和国特别行政区)
|
Macao | MAC | Asia | Eastern Asia | 473000 |
 圣马丁
圣马丁
|
Saint Martin | MAF | Americas | Caribbean | 38659 |
 摩洛哥
摩洛哥
|
Morocco | MAR | Africa | Northern Africa | 28351000 |
 摩纳哥
摩纳哥
|
Monaco | MCO | Europe | Western Europe | 34000 |
 摩尔多瓦
摩尔多瓦
|
Moldova | MDA | Europe | Eastern Europe | 4380000 |
 马达加斯加
马达加斯加
|
Madagascar | MDG | Africa | Eastern Africa | 15942000 |
 马尔代夫
马尔代夫
|
Maldives | MDV | Asia | Southern and Central Asia | 286000 |
 墨西哥
墨西哥
|
Mexico | MEX | North America | Central America | 98881000 |
 马绍尔群岛
马绍尔群岛
|
Marshall Islands | MHL | Oceania | Micronesia | 64000 |
 北马其顿
北马其顿
|
Macedonia | MKD | Europe | Southern Europe | 2024000 |
 马里
马里
|
Mali | MLI | Africa | Western Africa | 11234000 |
 马耳他
马耳他
|
Malta | MLT | Europe | Southern Europe | 380200 |
 缅甸
缅甸
|
Myanmar | MMR | Asia | Southeast Asia | 45611000 |
 黑山
黑山
|
Montenegro | MNE | Europe | Southeast Europe | 621718 |
 蒙古
蒙古
|
Mongolia | MNG | Asia | Eastern Asia | 2662000 |
 北马里亚纳群岛
北马里亚纳群岛
|
Northern Mariana Islands | MNP | Oceania | Micronesia | 78000 |
 莫桑比克
莫桑比克
|
Mozambique | MOZ | Africa | Eastern Africa | 19680000 |
 毛里塔尼亚
毛里塔尼亚
|
Mauritania | MRT | Africa | Western Africa | 2670000 |
 蒙特塞拉特
蒙特塞拉特
|
Montserrat | MSR | North America | Caribbean | 11000 |
 马提尼克岛
马提尼克岛
|
Martinique | MTQ | North America | Caribbean | 395000 |
 毛里求斯
毛里求斯
|
Mauritius | MUS | Africa | Eastern Africa | 1158000 |
 马拉维
马拉维
|
Malawi | MWI | Africa | Eastern Africa | 10925000 |
 马来西亚
马来西亚
|
Malaysia | MYS | Asia | Southeast Asia | 22244000 |
 马约
马约
|
Mayotte | MYT | Africa | Eastern Africa | 149000 |
 纳米比亚
纳米比亚
|
Namibia | NAM | Africa | Southern Africa | 1726000 |
 新喀里多尼亚
新喀里多尼亚
|
New Caledonia | NCL | Oceania | Melanesia | 214000 |
 尼日尔
尼日尔
|
Niger | NER | Africa | Western Africa | 10730000 |
 诺福克岛
诺福克岛
|
Norfolk Island | NFK | Oceania | Australia and New Zealand | 2000 |
 尼日利亚
尼日利亚
|
Nigeria | NGA | Africa | Western Africa | 111506000 |
 尼加拉瓜
尼加拉瓜
|
Nicaragua | NIC | North America | Central America | 5074000 |
 纽埃
纽埃
|
Niue | NIU | Oceania | Polynesia | 2000 |
 荷兰
荷兰
|
Netherlands | NLD | Europe | Western Europe | 15864000 |
 挪威
挪威
|
Norway | NOR | Europe | Nordic Countries | 4478500 |
 尼泊尔
尼泊尔
|
Nepal | NPL | Asia | Southern and Central Asia | 23930000 |
 瑙鲁
瑙鲁
|
Nauru | NRU | Oceania | Micronesia | 12000 |
 新西兰
新西兰
|
New Zealand | NZL | Oceania | Australia and New Zealand | 3862000 |
 阿曼
阿曼
|
Oman | OMN | Asia | Middle East | 2542000 |
 巴基斯坦
巴基斯坦
|
Pakistan | PAK | Asia | Southern and Central Asia | 156483000 |
 巴拿马
巴拿马
|
Panama | PAN | North America | Central America | 2856000 |
 皮特凯恩群岛
皮特凯恩群岛
|
Pitcairn | PCN | Oceania | Polynesia | 50 |
 秘鲁
秘鲁
|
Peru | PER | South America | South America | 25662000 |
 菲律宾
菲律宾
|
Philippines | PHL | Asia | Southeast Asia | 75967000 |
 贝劳
贝劳
|
Palau | PLW | Oceania | Micronesia | 19000 |
 巴布亚新几内亚
巴布亚新几内亚
|
Papua New Guinea | PNG | Oceania | Melanesia | 4807000 |
 波兰
波兰
|
Poland | POL | Europe | Eastern Europe | 38653600 |
 波多黎各
波多黎各
|
Puerto Rico | PRI | North America | Caribbean | 3869000 |
 北朝鲜
北朝鲜
|
North Korea | PRK | Asia | Eastern Asia | 24039000 |
 葡萄牙
葡萄牙
|
Portugal | PRT | Europe | Southern Europe | 9997600 |
 巴拉圭
巴拉圭
|
Paraguay | PRY | South America | South America | 5496000 |
 巴勒斯坦
巴勒斯坦
|
Palestine | PSE | Asia | Middle East | 3101000 |
 法属波利尼西亚海外属地
法属波利尼西亚海外属地
|
French Polynesia | PYF | Oceania | Polynesia | 235000 |
 卡塔尔
卡塔尔
|
Qatar | QAT | Asia | Middle East | 599000 |
 留尼汪
留尼汪
|
Réunion | REU | Africa | Eastern Africa | 699000 |
 罗马尼亚
罗马尼亚
|
Romania | ROM | Europe | Eastern Europe | 22455500 |
 俄罗斯联邦
俄罗斯联邦
|
Russian Federation | RUS | Europe | Eastern Europe | 146934000 |
 卢旺达
卢旺达
|
Rwanda | RWA | Africa | Eastern Africa | 7733000 |
 沙特阿拉伯
沙特阿拉伯
|
Saudi Arabia | SAU | Asia | Middle East | 21607000 |
 苏丹
苏丹
|
Sudan | SDN | Africa | Northern Africa | 29490000 |
 塞内加尔
塞内加尔
|
Senegal | SEN | Africa | Western Africa | 9481000 |
 新加坡
新加坡
|
Singapore | SGP | Asia | Southeast Asia | 3567000 |
 南乔治亚岛和南桑威奇群岛
南乔治亚岛和南桑威奇群岛
|
South Georgia and the South Sandwich Islands | SGS | Antarctica | Antarctica | 0 |
 圣赫勒拿岛
圣赫勒拿岛
|
Saint Helena | SHN | Africa | Western Africa | 6000 |
 斯瓦尔巴特和扬马延岛
斯瓦尔巴特和扬马延岛
|
Svalbard and Jan Mayen | SJM | Europe | Nordic Countries | 3200 |
 所罗门群岛
所罗门群岛
|
Solomon Islands | SLB | Oceania | Melanesia | 444000 |
 塞拉利昂
塞拉利昂
|
Sierra Leone | SLE | Africa | Western Africa | 4854000 |
 萨尔瓦多
萨尔瓦多
|
El Salvador | SLV | North America | Central America | 6276000 |
 圣马力诺
圣马力诺
|
San Marino | SMR | Europe | Southern Europe | 27000 |
 索马里
索马里
|
Somalia | SOM | Africa | Eastern Africa | 10097000 |
 圣皮埃尔岛和密克隆岛
圣皮埃尔岛和密克隆岛
|
Saint Pierre and Miquelon | SPM | North America | North America | 7000 |
 塞尔维亚
塞尔维亚
|
Serbia | SRB | Europe | Southeast Europe | 6908224 |
 南苏丹
南苏丹
|
South Sudan | SSD | Africa | Middle Africa | 11193729 |
 圣多美和普林西比
圣多美和普林西比
|
Sao Tome and Principe | STP | Africa | Central Africa | 147000 |
 苏里南
苏里南
|
Suriname | SUR | South America | South America | 417000 |
 斯洛伐克
斯洛伐克
|
Slovakia | SVK | Europe | Eastern Europe | 5398700 |
 斯洛文尼亚
斯洛文尼亚
|
Slovenia | SVN | Europe | Southern Europe | 1987800 |
 瑞典
瑞典
|
Sweden | SWE | Europe | Nordic Countries | 8861400 |
 斯威士兰
斯威士兰
|
Swaziland | SWZ | Africa | Southern Africa | 1008000 |
 圣马丁岛
圣马丁岛
|
Sint Maarten | SXM | Americas | Caribbean | 40812 |
 塞舌尔
塞舌尔
|
Seychelles | SYC | Africa | Eastern Africa | 77000 |
 叙利亚
叙利亚
|
Syria | SYR | Asia | Middle East | 16125000 |
 特克斯和凯科斯群岛
特克斯和凯科斯群岛
|
Turks and Caicos Islands | TCA | North America | Caribbean | 17000 |
 乍得
乍得
|
Chad | TCD | Africa | Central Africa | 7651000 |
 多哥
多哥
|
Togo | TGO | Africa | Western Africa | 4629000 |
 泰国
泰国
|
Thailand | THA | Asia | Southeast Asia | 61399000 |
 塔吉克斯坦
塔吉克斯坦
|
Tajikistan | TJK | Asia | Southern and Central Asia | 6188000 |
 托克劳
托克劳
|
Tokelau | TKL | Oceania | Polynesia | 2000 |
 土库曼斯坦
土库曼斯坦
|
Turkmenistan | TKM | Asia | Southern and Central Asia | 4459000 |
 东帝汶
东帝汶
|
Timor-Leste | TLS | Asia | South-Eastern Asia | 1318442 |
|
|
East Timor | TMP | Asia | Southeast Asia | 885000 |
 汤加
汤加
|
Tonga | TON | Oceania | Polynesia | 99000 |
 特立尼达和多巴哥
特立尼达和多巴哥
|
Trinidad and Tobago | TTO | North America | Caribbean | 1295000 |
 突尼斯
突尼斯
|
Tunisia | TUN | Africa | Northern Africa | 9586000 |
 土耳其
土耳其
|
Turkey | TUR | Asia | Middle East | 66591000 |
 图瓦卢
图瓦卢
|
Tuvalu | TUV | Oceania | Polynesia | 12000 |
 中国台湾
中国台湾
|
Taiwan | TWN | Asia | Eastern Asia | 22256000 |
 坦桑尼亚
坦桑尼亚
|
Tanzania | TZA | Africa | Eastern Africa | 33517000 |
 乌干达
乌干达
|
Uganda | UGA | Africa | Eastern Africa | 21778000 |
 乌克兰
乌克兰
|
Ukraine | UKR | Europe | Eastern Europe | 50456000 |
 美国本土外小岛屿
美国本土外小岛屿
|
United States Minor Outlying Islands | UMI | Oceania | Micronesia/Caribbean | 0 |
 科索沃
科索沃
|
Kosovo | UNK | Europe | Southeast Europe | 1775378 |
 乌拉圭
乌拉圭
|
Uruguay | URY | South America | South America | 3337000 |
 美国
美国
|
United States | USA | North America | North America | 278357000 |
 乌兹别克斯坦
乌兹别克斯坦
|
Uzbekistan | UZB | Asia | Southern and Central Asia | 24318000 |
 梵蒂冈
梵蒂冈
|
Holy See (Vatican City State) | VAT | Europe | Southern Europe | 1000 |
 圣文森特和格林纳丁斯
圣文森特和格林纳丁斯
|
Saint Vincent and the Grenadines | VCT | North America | Caribbean | 114000 |
 委内瑞拉
委内瑞拉
|
Venezuela | VEN | South America | South America | 24170000 |
 英属维尔京群岛
英属维尔京群岛
|
Virgin Islands, British | VGB | North America | Caribbean | 21000 |
 美属维尔京群岛
美属维尔京群岛
|
Virgin Islands, U.S. | VIR | North America | Caribbean | 93000 |
 越南
越南
|
Vietnam | VNM | Asia | Southeast Asia | 79832000 |
 瓦努阿图
瓦努阿图
|
Vanuatu | VUT | Oceania | Melanesia | 190000 |
 瓦利斯和富图纳
瓦利斯和富图纳
|
Wallis and Futuna | WLF | Oceania | Polynesia | 15000 |
 萨摩亚
萨摩亚
|
Samoa | WSM | Oceania | Polynesia | 180000 |
 也门
也门
|
Yemen | YEM | Asia | Middle East | 18112000 |
 南斯拉夫
南斯拉夫
|
Yugoslavia | YUG | Europe | Southern Europe | 10640000 |
 南非
南非
|
South Africa | ZAF | Africa | Southern Africa | 40377000 |
 赞比亚
赞比亚
|
Zambia | ZMB | Africa | Eastern Africa | 9169000 |
 津巴布韦
津巴布韦
|
Zimbabwe | ZWE | Africa | Eastern Africa | 11669000 |