今天是:
带着程序的旅程,每一行代码都是你前进的一步,每个错误都是你成长的机会,最终,你将抵达你的目的地。
zookeeper
1.zookeeper概述
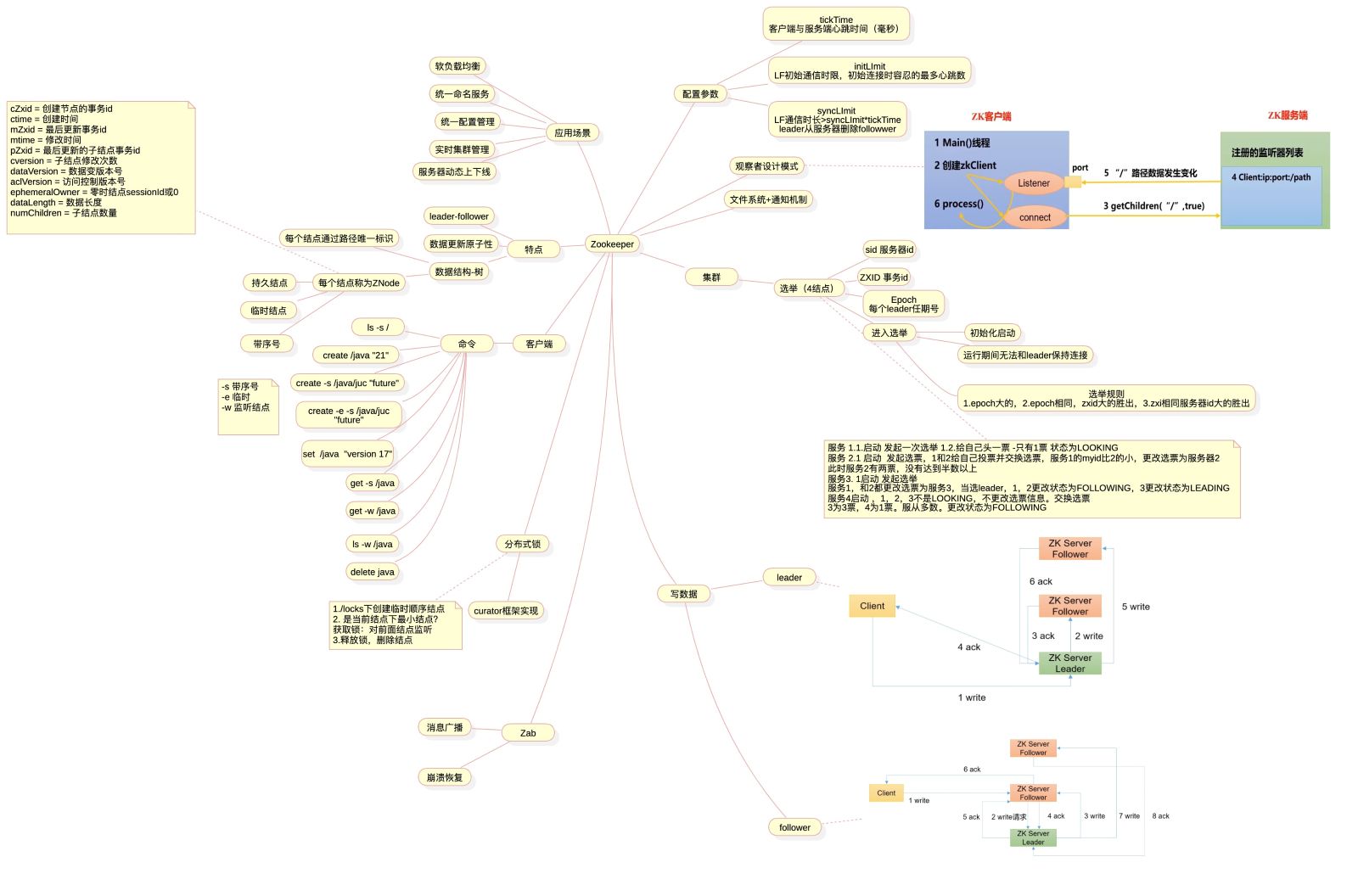
2.服务端逻辑处理
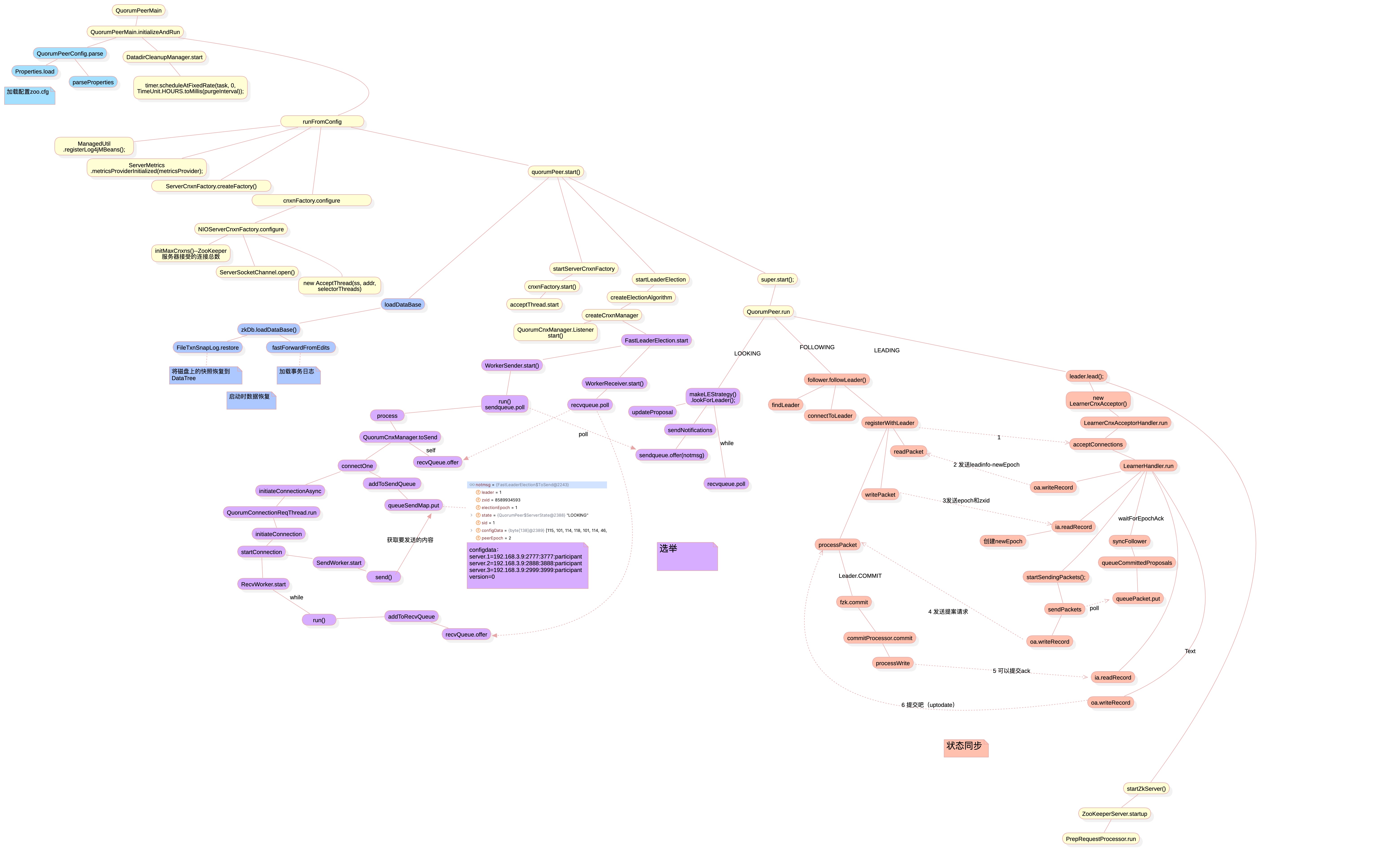
2.1配置文件解析
读取zoo.cfg并解析到Properties中
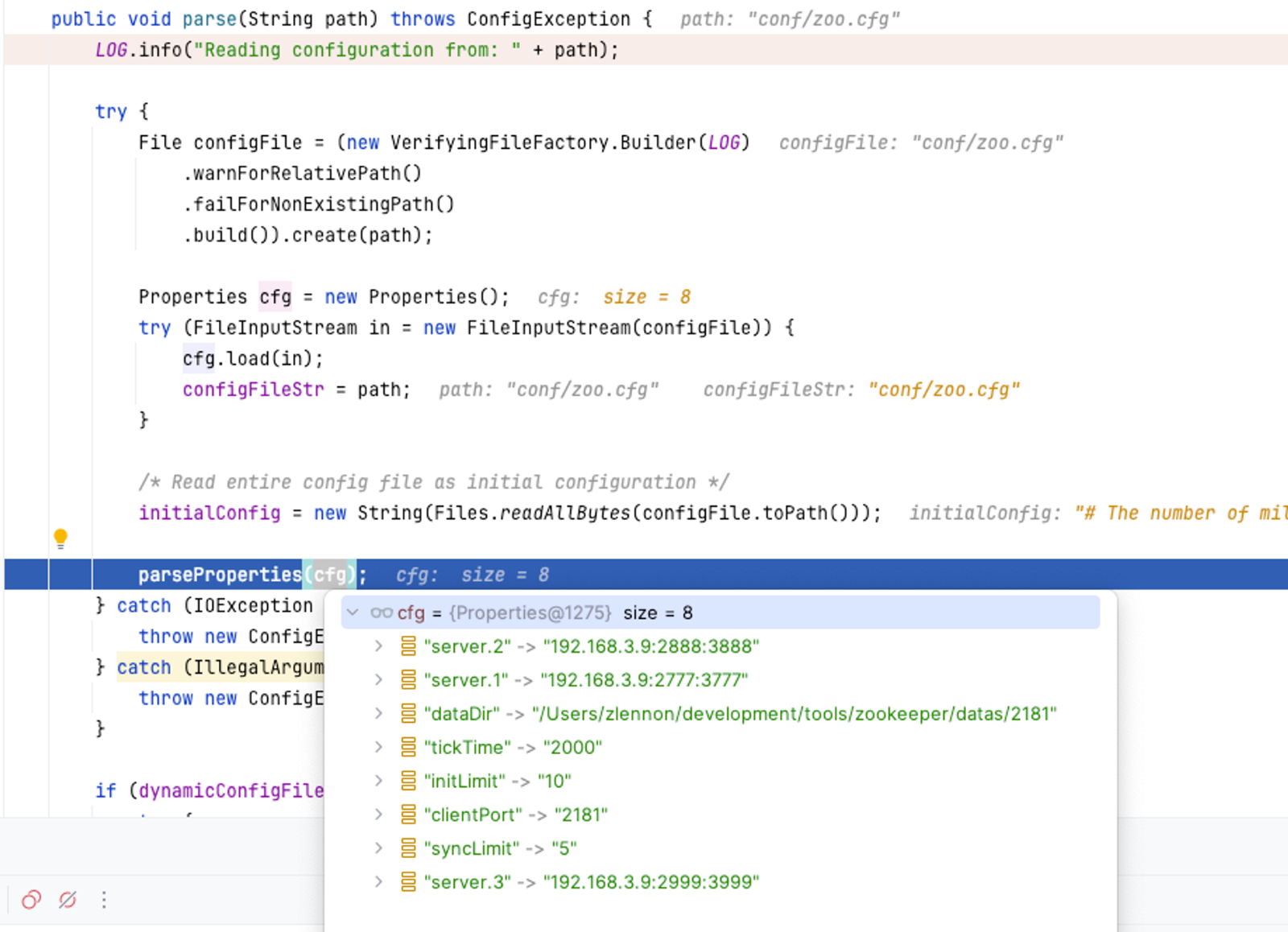
2.2日志恢复
快照日志加载
服务启动时会将快照日志加载到内存中,并解析为DataTree。
快照日志查看,使用zkSnapShotToolkit.sh可以查看快照日志,快照日志的结构如下
ZNode Details (count=5):
----
/
cZxid = 0x00000000000000
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x00000000000000
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x00000000000000
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x00000000000000
dataLength = 0
----
/zookeeper
cZxid = 0x00000000000000
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x00000000000000
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x00000000000000
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x00000000000000
dataLength = 0
----
/zookeeper/config
cZxid = 0x00000000000000
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x00000000000000
mtime = Sat Jan 20 09:44:12 CST 2024
pZxid = 0x00000000000000
cversion = 0
dataVersion = -1
aclVersion = -1
ephemeralOwner = 0x00000000000000
dataLength = 138
----
/zookeeper/quota
cZxid = 0x00000000000000
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x00000000000000
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x00000000000000
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x00000000000000
dataLength = 0
----
Session Details (sid, timeout, ephemeralCount):
----
Last zxid: 0x100000000
事务日志
事务日志可用zkTxnLogToolkit.sh查看,结构如下
24-1-20 下午10时19分12秒 session 0x100166521450009 cxid 0x6 zxid 0x100000022 delete '/lockPath/compute
24-1-20 下午10时19分12秒 session 0x100166521450009 cxid 0x7 zxid 0x100000023 create2 /lockPath/compute,192.168.3.9,[31,s{'world,'anyone}
],true,7
24-1-20 下午10时19分13秒 session 0x100166521450009 cxid 0x9 zxid 0x100000024 delete '/lockPath/compute
24-1-20 下午10时19分13秒 session 0x100166521450009 cxid 0xa zxid 0x100000025 create2 /lockPath/compute,192.168.3.9,[31,s{'world,'anyone}
],true,8
24-1-20 下午10时19分13秒 session 0x100166521450009 cxid 0xc zxid 0x100000026 delete '/lockPath/compute
24-1-20 下午10时19分13秒 session 0x100166521450009 cxid 0xd zxid 0x100000027 create2 /lockPath/compute,192.168.3.9,[31,s{'world,'anyone}
],true,9
24-1-20 下午10时19分13秒 session 0x100166521450009 cxid 0xf zxid 0x100000028 delete '/lockPath/compute
24-1-20 下午10时19分13秒 session 0x100166521450009 cxid 0x10 zxid 0x100000029 create2 /lockPath/compute,192.168.3.9,[31,s{'world,'anyone}
],true,10
24-1-20 下午10时19分14秒 session 0x100166521450009 cxid 0x12 zxid 0x10000002a delete '/lockPath/compute
24-1-20 下午10时19分14秒 session 0x100166521450009 cxid 0x14 zxid 0x10000002b closeSession v{}
24-1-21 上午09时23分30秒 session 0x100166521450004 cxid 0x0 zxid 0x10000002c closeSession v{}
24-1-21 上午09时49分20秒 session 0x10016652145000a cxid 0x0 zxid 0x10000002d createSession 30000
24-1-21 上午09时49分52秒 session 0x10016652145000a cxid 0x0 zxid 0x10000002e closeSession v{}
24-1-21 下午02时01分21秒 session 0x10016652145000b cxid 0x0 zxid 0x10000002f createSession 30000
24-1-21 下午02时01分52秒 session 0x10016652145000b cxid 0x0 zxid 0x100000030 closeSession v{}
24-1-21 下午03时25分16秒 session 0x100166521450003 cxid 0x0 zxid 0x100000031 closeSession v{}
24-1-21 下午03时25分16秒 session 0x100166521450006 cxid 0x0 zxid 0x100000032 closeSession v{}
2.3选举
见上图紫色部分
1.服务启动时状态是LOOKING,先给自己增加投票`logicalclock.incrementAndGet()`, 给集群中的结点发送投票通知`sendNotifications`。while循环等待集群中的其他结点投票通知
public Vote lookForLeader() throws InterruptedException {
try {
self.jmxLeaderElectionBean = new LeaderElectionBean();
MBeanRegistry.getInstance().register(self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
self.jmxLeaderElectionBean = null;
}
self.start_fle = Time.currentElapsedTime();
try {
/*
* The votes from the current leader election are stored in recvset. In other words, a vote v is in recvset
* if v.electionEpoch == logicalclock. The current participant uses recvset to deduce on whether a majority
* of participants has voted for it.
*/
Map<Long, Vote> recvset = new HashMap<>();
/*
* The votes from previous leader elections, as well as the votes from the current leader election are
* stored in outofelection. Note that notifications in a LOOKING state are not stored in outofelection.
* Only FOLLOWING or LEADING notifications are stored in outofelection. The current participant could use
* outofelection to learn which participant is the leader if it arrives late (i.e., higher logicalclock than
* the electionEpoch of the received notifications) in a leader election.
*/
Map<Long, Vote> outofelection = new HashMap<>();
int notTimeout = minNotificationInterval;
synchronized (this) {
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
LOG.info(
"New election. My id = {}, proposed zxid=0x{}",
self.getMyId(),
Long.toHexString(proposedZxid));
sendNotifications();
SyncedLearnerTracker voteSet = null;
/*
* Loop in which we exchange notifications until we find a leader
*/
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
/*
* Remove next notification from queue, times out after 2 times
* the termination time
*/
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough.
* Otherwise processes new notification.
*/
if (n == null) {
if (manager.haveDelivered()) {
sendNotifications();
} else {
manager.connectAll();
}
/*
* Exponential backoff
*/
notTimeout = Math.min(notTimeout << 1, maxNotificationInterval);
/*
* When a leader failure happens on a master, the backup will be supposed to receive the honour from
* Oracle and become a leader, but the honour is likely to be delay. We do a re-check once timeout happens
*
* The leader election algorithm does not provide the ability of electing a leader from a single instance
* which is in a configuration of 2 instances.
* */
if (self.getQuorumVerifier() instanceof QuorumOracleMaj
&& self.getQuorumVerifier().revalidateVoteset(voteSet, notTimeout != minNotificationInterval)) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
LOG.info("Notification time out: {} ms", notTimeout);
} else if (validVoter(n.sid) && validVoter(n.leader)) {
/*
* Only proceed if the vote comes from a replica in the current or next
* voting view for a replica in the current or next voting view.
*/
switch (n.state) {
case LOOKING:
if (getInitLastLoggedZxid() == -1) {
LOG.debug("Ignoring notification as our zxid is -1");
break;
}
if (n.zxid == -1) {
LOG.debug("Ignoring notification from member with -1 zxid {}", n.sid);
break;
}
// If notification > current, replace and send messages out
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
LOG.debug(
"Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x{}, logicalclock=0x{}",
Long.toHexString(n.electionEpoch),
Long.toHexString(logicalclock.get()));
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
LOG.debug(
"Adding vote: from={}, proposed leader={}, proposed zxid=0x{}, proposed election epoch=0x{}",
n.sid,
n.leader,
Long.toHexString(n.zxid),
Long.toHexString(n.electionEpoch));
// don't care about the version if it's in LOOKING state
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
if (voteSet.hasAllQuorums()) {
// Verify if there is any change in the proposed leader
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*/
if (n == null) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
LOG.debug("Notification from observer: {}", n.sid);
break;
/*
* In ZOOKEEPER-3922, we separate the behaviors of FOLLOWING and LEADING.
* To avoid the duplication of codes, we create a method called followingBehavior which was used to
* shared by FOLLOWING and LEADING. This method returns a Vote. When the returned Vote is null, it follows
* the original idea to break swtich statement; otherwise, a valid returned Vote indicates, a leader
* is generated.
*
* The reason why we need to separate these behaviors is to make the algorithm runnable for 2-node
* setting. An extra condition for generating leader is needed. Due to the majority rule, only when
* there is a majority in the voteset, a leader will be generated. However, in a configuration of 2 nodes,
* the number to achieve the majority remains 2, which means a recovered node cannot generate a leader which is
* the existed leader. Therefore, we need the Oracle to kick in this situation. In a two-node configuration, the Oracle
* only grants the permission to maintain the progress to one node. The oracle either grants the permission to the
* remained node and makes it a new leader when there is a faulty machine, which is the case to maintain the progress.
* Otherwise, the oracle does not grant the permission to the remained node, which further causes a service down.
*
* In the former case, when a failed server recovers and participate in the leader election, it would not locate a
* new leader because there does not exist a majority in the voteset. It fails on the containAllQuorum() infinitely due to
* two facts. First one is the fact that it does do not have a majority in the voteset. The other fact is the fact that
* the oracle would not give the permission since the oracle already gave the permission to the existed leader, the healthy machine.
* Logically, when the oracle replies with negative, it implies the existed leader which is LEADING notification comes from is a valid leader.
* To threat this negative replies as a permission to generate the leader is the purpose to separate these two behaviors.
*
*
* */
case FOLLOWING:
/*
* To avoid duplicate codes
* */
Vote resultFN = receivedFollowingNotification(recvset, outofelection, voteSet, n);
if (resultFN == null) {
break;
} else {
return resultFN;
}
case LEADING:
/*
* In leadingBehavior(), it performs followingBehvior() first. When followingBehavior() returns
* a null pointer, ask Oracle whether to follow this leader.
* */
Vote resultLN = receivedLeadingNotification(recvset, outofelection, voteSet, n);
if (resultLN == null) {
break;
} else {
return resultLN;
}
default:
LOG.warn("Notification state unrecognized: {} (n.state), {}(n.sid)", n.state, n.sid);
break;
}
} else {
if (!validVoter(n.leader)) {
LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
}
if (!validVoter(n.sid)) {
LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
}
}
}
return null;
} finally {
try {
if (self.jmxLeaderElectionBean != null) {
MBeanRegistry.getInstance().unregister(self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
LOG.debug("Number of connection processing threads: {}", manager.getConnectionThreadCount());
}
}
2.RecvWorker从sokcet中读取其他结点发送的投票通知并放入recvQueue,WorkerReceiver从队列中获取并处理投票。
class WorkerReceiver extends ZooKeeperThread {
volatile boolean stop;
QuorumCnxManager manager;
WorkerReceiver(QuorumCnxManager manager) {
super("WorkerReceiver");
this.stop = false;
this.manager = manager;
}
public void run() {
Message response;
while (!stop) {
// Sleeps on receive
try {
response = manager.pollRecvQueue(3000, TimeUnit.MILLISECONDS);
if (response == null) {
continue;
}
final int capacity = response.buffer.capacity();
// The current protocol and two previous generations all send at least 28 bytes
if (capacity < 28) {
LOG.error("Got a short response from server {}: {}", response.sid, capacity);
continue;
}
// this is the backwardCompatibility mode in place before ZK-107
// It is for a version of the protocol in which we didn't send peer epoch
// With peer epoch and version the message became 40 bytes
boolean backCompatibility28 = (capacity == 28);
// this is the backwardCompatibility mode for no version information
boolean backCompatibility40 = (capacity == 40);
response.buffer.clear();
// Instantiate Notification and set its attributes
Notification n = new Notification();
int rstate = response.buffer.getInt();
long rleader = response.buffer.getLong();
long rzxid = response.buffer.getLong();
long relectionEpoch = response.buffer.getLong();
long rpeerepoch;
int version = 0x0;
QuorumVerifier rqv = null;
try {
if (!backCompatibility28) {
rpeerepoch = response.buffer.getLong();
if (!backCompatibility40) {
/*
* Version added in 3.4.6
*/
version = response.buffer.getInt();
} else {
LOG.info("Backward compatibility mode (36 bits), server id: {}", response.sid);
}
} else {
LOG.info("Backward compatibility mode (28 bits), server id: {}", response.sid);
rpeerepoch = ZxidUtils.getEpochFromZxid(rzxid);
}
// check if we have a version that includes config. If so extract config info from message.
if (version > 0x1) {
int configLength = response.buffer.getInt();
// we want to avoid errors caused by the allocation of a byte array with negative length
// (causing NegativeArraySizeException) or huge length (causing e.g. OutOfMemoryError)
if (configLength < 0 || configLength > capacity) {
throw new IOException(String.format("Invalid configLength in notification message! sid=%d, capacity=%d, version=%d, configLength=%d",
response.sid, capacity, version, configLength));
}
byte[] b = new byte[configLength];
response.buffer.get(b);
synchronized (self) {
try {
rqv = self.configFromString(new String(b, UTF_8));
QuorumVerifier curQV = self.getQuorumVerifier();
if (rqv.getVersion() > curQV.getVersion()) {
LOG.info("{} Received version: {} my version: {}",
self.getMyId(),
Long.toHexString(rqv.getVersion()),
Long.toHexString(self.getQuorumVerifier().getVersion()));
if (self.getPeerState() == ServerState.LOOKING) {
LOG.debug("Invoking processReconfig(), state: {}", self.getServerState());
self.processReconfig(rqv, null, null, false);
if (!rqv.equals(curQV)) {
LOG.info("restarting leader election");
self.shuttingDownLE = true;
self.getElectionAlg().shutdown();
break;
}
} else {
LOG.debug("Skip processReconfig(), state: {}", self.getServerState());
}
}
} catch (IOException | ConfigException e) {
LOG.error("Something went wrong while processing config received from {}", response.sid);
}
}
} else {
LOG.info("Backward compatibility mode (before reconfig), server id: {}", response.sid);
}
} catch (BufferUnderflowException | IOException e) {
LOG.warn("Skipping the processing of a partial / malformed response message sent by sid={} (message length: {})",
response.sid, capacity, e);
continue;
}
/*
* If it is from a non-voting server (such as an observer or
* a non-voting follower), respond right away.
*/
if (!validVoter(response.sid)) {
Vote current = self.getCurrentVote();
QuorumVerifier qv = self.getQuorumVerifier();
ToSend notmsg = new ToSend(
ToSend.mType.notification,
current.getId(),
current.getZxid(),
logicalclock.get(),
self.getPeerState(),
response.sid,
current.getPeerEpoch(),
qv.toString().getBytes(UTF_8));
sendqueue.offer(notmsg);
} else {
// Receive new message
LOG.debug("Receive new notification message. My id = {}", self.getMyId());
// State of peer that sent this message
QuorumPeer.ServerState ackstate = QuorumPeer.ServerState.LOOKING;
switch (rstate) {
case 0:
ackstate = QuorumPeer.ServerState.LOOKING;
break;
case 1:
ackstate = QuorumPeer.ServerState.FOLLOWING;
break;
case 2:
ackstate = QuorumPeer.ServerState.LEADING;
break;
case 3:
ackstate = QuorumPeer.ServerState.OBSERVING;
break;
default:
continue;
}
n.leader = rleader;
n.zxid = rzxid;
n.electionEpoch = relectionEpoch;
n.state = ackstate;
n.sid = response.sid;
n.peerEpoch = rpeerepoch;
n.version = version;
n.qv = rqv;
/*
* Print notification info
*/
LOG.info(
"Notification: my state:{}; n.sid:{}, n.state:{}, n.leader:{}, n.round:0x{}, "
+ "n.peerEpoch:0x{}, n.zxid:0x{}, message format version:0x{}, n.config version:0x{}",
self.getPeerState(),
n.sid,
n.state,
n.leader,
Long.toHexString(n.electionEpoch),
Long.toHexString(n.peerEpoch),
Long.toHexString(n.zxid),
Long.toHexString(n.version),
(n.qv != null ? (Long.toHexString(n.qv.getVersion())) : "0"));
/*
* If this server is looking, then send proposed leader
*/
if (self.getPeerState() == QuorumPeer.ServerState.LOOKING) {
recvqueue.offer(n);
/*
* Send a notification back if the peer that sent this
* message is also looking and its logical clock is
* lagging behind.
*/
if ((ackstate == QuorumPeer.ServerState.LOOKING)
&& (n.electionEpoch < logicalclock.get())) {
Vote v = getVote();
QuorumVerifier qv = self.getQuorumVerifier();
ToSend notmsg = new ToSend(
ToSend.mType.notification,
v.getId(),
v.getZxid(),
logicalclock.get(),
self.getPeerState(),
response.sid,
v.getPeerEpoch(),
qv.toString().getBytes());
sendqueue.offer(notmsg);
}
} else {
/*
* If this server is not looking, but the one that sent the ack
* is looking, then send back what it believes to be the leader.
*/
Vote current = self.getCurrentVote();
if (ackstate == QuorumPeer.ServerState.LOOKING) {
if (self.leader != null) {
if (leadingVoteSet != null) {
self.leader.setLeadingVoteSet(leadingVoteSet);
leadingVoteSet = null;
}
self.leader.reportLookingSid(response.sid);
}
LOG.debug(
"Sending new notification. My id ={} recipient={} zxid=0x{} leader={} config version = {}",
self.getMyId(),
response.sid,
Long.toHexString(current.getZxid()),
current.getId(),
Long.toHexString(self.getQuorumVerifier().getVersion()));
QuorumVerifier qv = self.getQuorumVerifier();
ToSend notmsg = new ToSend(
ToSend.mType.notification,
current.getId(),
current.getZxid(),
current.getElectionEpoch(),
self.getPeerState(),
response.sid,
current.getPeerEpoch(),
qv.toString().getBytes());
sendqueue.offer(notmsg);
}
}
}
} catch (InterruptedException e) {
LOG.warn("Interrupted Exception while waiting for new message", e);
}
}
LOG.info("WorkerReceiver is down");
}
}
2.4状态同步
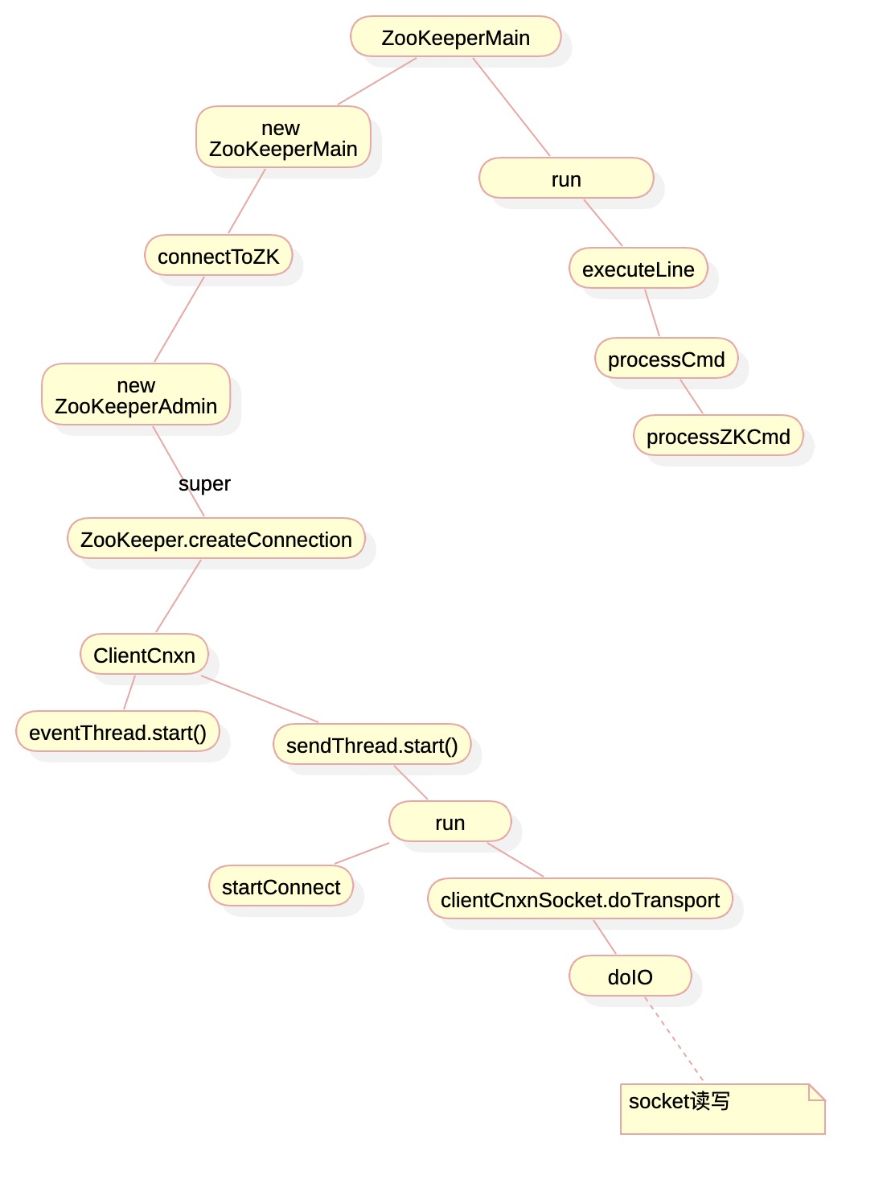
3.客户端源码分析
{kind=link}